Chip Huyen:开发AI产品时的六大常见陷阱
2025年6月11日
作者简介:从越南农村走出的全球机器学习系统设计领域的权威专家,Claypot AI联合创始人。花三年时间环游世界并写作,创办公司并成功出售,曾为NVIDIA、Netflix、Snorkel AI等知名科技公司提供服务,著有畅销书《Designing Machine Learning Systems》。
我们现在仍处于基础模型应用开发的早期阶段,犯错误很正常。这里总结了一些最常见的陷阱,既来自公开案例研究,也来自我的个人经验。
这些陷阱很常见,如果你从事过AI产品工作,很可能已经见过。
(名词解释:生成式 AI(GenAI)是指用大模型生成文本、图像、音频、视频等内容的技术。)
01|不需要生成式AI时,却强制用
每当有新技术出现,我都能听到资深工程师们的集体叹息:"不是所有问题都是钉子。"
生成式AI也不例外,它看似无限的能力只会加剧用生成式AI解决一切问题的倾向。
有个团队向我推荐了一个用生成式AI优化能耗的想法。他们把家庭高耗能活动清单和每小时电价输入AI,然后让它提供一个最小化电费成本的建议。
实验显示,这能帮助家庭减少30%的电费。白送的钱,谁不想用他们的应用呢?
我问:"这和简单地把最耗能的活动,安排在电价最便宜的时候相比如何?比如晚上10点后洗衣服和给车充电?"
他们说会试试,然后告诉我结果。但他们再也没回复,很快就放弃了这个应用。
我怀疑调度算法可能非常有效。即使不够有效,也有其他比生成式AI更便宜、更可靠的优化解决方案,比如线性规划。
我见过无数次这种情况。
某大公司想用生成式AI检测网络流量异常。另一家想预测客户呼叫量,某医院想检测患者是否营养不良(真的不推荐)。
实用AI大模型,探索新方法,了解解决问题的可能性,往往是有益的,只要你清楚自己的目标不是解决问题,而是测试解决方案。
"我们解决了问题"和"我们使用生成式AI"是两个截然不同的事情,遗憾的是,太多人更愿意要后者。
02|把糟糕的产品当成糟糕的AI
在另一个极端,许多团队因为试用生成式AI后用户讨厌它,就认为生成式AI不是他们问题的有效解决方案。
然而,其他团队在类似用例上,成功使用了生成式AI。我观察了其中两个团队,在这两个案例中,问题不在于AI,而在于产品。
许多人告诉我,他们调用AI技术方面,很直接(调用API)。困难的部分是用户体验(UX)。产品界面应该是什么样子?如何将产品无缝集成到用户工作流程中?如何融入人在回路中的机制?
良好的用户体验一直很有挑战性,对生成式AI来说更是如此。
虽然我们知道生成式AI正在改变我们阅读、写作、学习、教学、工作、娱乐等方式,但我们还不完全知道具体如何改变。
未来的阅读/学习/工作会是什么样子?
这里有些简单例子,说明用户想要的可能是反直觉的,为此你需要深度洞察用户需求。
案例一:我朋友开发了一个总结会议记录的应用。最初,她的团队专注于找到合适的摘要长度:用户更喜欢3句话摘要,还是5句话摘要?
然而,结果发现用户并不关心摘要长度,他们只想要每次会议中,针对自己的部分,自己需要干什么。
案例二:当LinkedIn开发技能匹配评估聊天机器人时,他们发现用户不想要正确的回答,用户想要有帮助的回答。
例如,如果用户问机器人,他们是否适合某个工作,机器人回答:"你完全不适合"。这个回答可能是正确的,但对用户并不是很有帮助。用户想要关于差距在哪里,以及如何弥补差距的建议。
案例三:Intuit构建了一个帮助用户回答税务问题的聊天机器人。
最初,他们得到了冷淡的市场反馈,用户觉得机器人没用。调查后发现,用户实际上讨厌打字,面对空白聊天机器人,用户不知道机器人能做什么,不知道该输入什么。
因此,在用户交互,Intuit都添加了几个建议问题,供用户点击。这减少了用户上手的成本,并逐渐建立了用户的信任。
用户的反馈随后变得积极得多。
现在大家都使用相同的大模型,AI产品的AI组件很相似,差异化在于对用户真实需求的把握程度。
03|起步就太复杂
这种陷阱的例子:
- 直接调用API就能解决时,却使用智能体框架。
- 基于简单的词汇检索解决方案(不需要向量数据库)就能工作时,却纠结于使用哪个向量数据库。
- 提示工程就能解决时,却坚持要微调。
- 使用语义缓存。
面对这么多闪亮的新技术,直接跳进去使用它们很诱人。
然而,过早引入外部工具可能造成两个问题:
- 忽视掉关键细节,让你难以理解和调试系统。
- 引入不必要的错误。
AI工具开发者可能会犯错误。例如,我在审查框架代码库时,经常在默认提示中发现拼写错误。
如果你使用的框架,在不告诉你的情况下更新了提示词,你的应用可能会改变,而你可能不知道为什么。
最终,模块化是好的。但模块化需要融入最佳实践并经过时间考验。由于我们仍处于AI工程早期阶段,最佳实践仍在演进,我们在采用任何抽象封装时都应该更加警惕。
04|过度依赖早期成功
案例一:LinkedIn花了1个月达到他们想要的80%用户体验,又花了4个月才超过95%。
初期成功让他们严重低估了,改进产品的难度,特别是在幻觉问题方面。他们发现每提高1%都如此困难,这让人沮丧。
案例二:一家为电商开发AI销售助手的初创公司告诉我,从0到80%,和从80%到90%花费的时间一样长。他们面临的挑战:
- 准确性/延迟权衡:更多规划/自我纠正 = 更多节点 = 更高延迟
- 工具调用:智能体难以区分相似工具
- 系统提示中的语调要求(如
"像奢侈品牌礼宾员那样说话")难以完美遵守 - 智能体难以完全理解客户意图
- 难以创建特定的单元测试集,因为查询组合基本上是无限的
案例三:在论文UltraChat中,Ding等人(2023)分享说"从0到60的旅程很容易,而从60到100变得极其困难。"
这可能是任何开发过AI产品的人,学到的痛苦教训之一。
构建演示很容易,但构建产品很难。
除了幻觉、延迟、延迟/准确性权衡、工具使用、提示工程、测试等问题,团队还会遇到以下问题:
-
API提供商的可靠性。有团队告诉我,他们API调用超时达到10%,或者因为底层模型变化,导致产品行为改变。
-
合规性。例如AI输出版权、数据访问/共享、用户隐私、检索/缓存系统的安全风险,以及训练数据来源的模糊性。
-
安全性。例如恶意行为者滥用你的产品,你的产品生成敏感或冒犯性回应。
在规划产品里程碑和资源时,确保考虑这些潜在障碍。
朋友称这为谨慎乐观。然而,记住许多酷炫的演示,并不能转化为出色的产品。
05|放弃人工评估
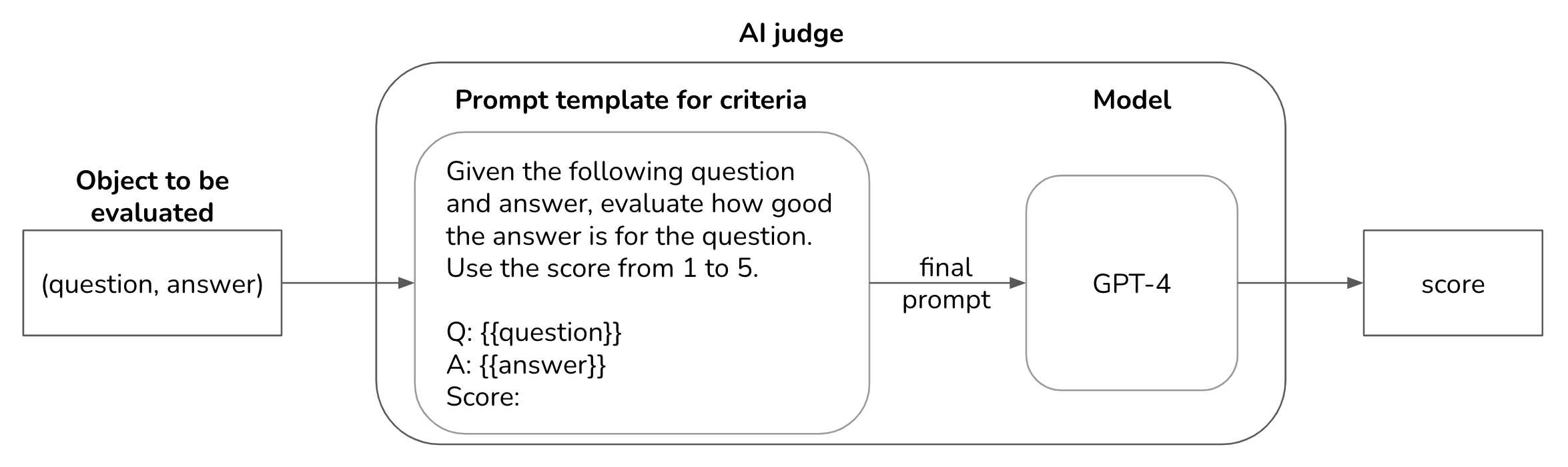
为了自动评估AI应用,许多团队选择AI作为评判者(也称为LLM作为评估者),使用AI模型评估AI输出。
常见陷阱是放弃人工评估,完全依赖AI评估产品。
虽然用AI评估非常有用,但它们不是确定性的。
质量取决于底层模型、提示词和用例。如果AI评判者开发不当,可能对你应用的性能,给出误导性评估。
AI作为评估者,必须像所有其他AI应用一样,经过评估和反复改进。
我见过的拥有最佳产品的团队,都有人工评估来补充自动评估。每天,他们让专家评估应用输出的一个子集,范围从30到1000个例子不等。
日常人工评估有三个目的:
-
将人类判断与AI判断关联。如果人类评估者的分数在下降,但AI评判者的分数在上升,你可能需要调查你的AI评判者。
-
更好地理解用户如何使用你的应用,这能给你改进应用的想法。
-
检测用户行为的模式和变化,利用你对当前事件的了解,这是自动数据探索可能错过的。
人工评估的可靠性也取决于精心制作的标注指南。这些标注指南可以帮助改进模型指令(如果人类难以遵循指令,模型也会如此)。
如果你选择微调,它也可以重复使用来创建微调数据。
在我参与的每个项目中,仅仅盯着数据看15分钟通常就能给我一些见解,可以为我节省数小时。Greg Brockman发推说:"人工检查数据,可能是机器学习中价值与声望比最高的活动。"
06|众包用例
这是我在企业疯狂采用生成式AI的早期,看到的错误。
由于无法制定专注于哪些用例的方法,许多技术高管众包想法(全员头脑风暴):"我们雇佣聪明人,让他们告诉我们该做什么。"
然后他们试图逐一实现这些想法。
这就是我们最终得到一百万个text-to-SQL模型、一百万个Slack机器人和十亿个代码插件的原因。
虽然倾听你雇佣的聪明人的想法,确实是个好主意,但个人可能偏向于,立即影响他们日常工作的问题,而不是可能带来最高投资回报的问题。
没有考虑大局的打法,很容易被一系列小的、低影响应用分散注意力,并得出生成式AI没有投资回报率的错误结论。
总结
简而言之,以下是常见的AI运用开发的陷阱:
-
不需要生成式AI时却要用生成式AI。生成式AI不是解决所有问题的万能方案。许多问题甚至不需要AI。
-
把糟糕的产品当成糟糕的AI。对许多AI产品来说,AI技术是容易的部分,洞察需求构建产品才是困难的部分。
-
起步就太复杂。虽然花哨的新框架,和微调对许多项目都有用,但它们不应该是你的首选行动方案。
-
过度依赖早期成功。初期成功可能是误导性的。从演示到生产,可能比演示花费更长时间。
-
放弃人工评估。AI自动评估的内容,应该经过验证,并与系统性人工评估相关联。
-
众包用例。从公司大局考虑,以最大化投资回报。
原文:https://huyenchip.com/2025/01/16/ai-engineering-pitfalls.html
作者简介:Chip Huye是一位越南裔作家和计算机科学家,专注生成式 AI 和机器学习系统设计,著有畅销书《Designing Machine Learning Systems》。