2024年最值得阅读的AI论文
2025年1月25日
来源:Ahead of AI
为了迎接新的一年,我终于完成了这篇关于2024年人工智能研究亮点的文章草稿。文章涵盖了多种主题,从专家混合模型到新的大规模语言模型(LLM)精度扩展法则。
回顾2024年的所有重大研究亮点,可能需要写一本完整的书。
这一年极其富有成效,即使对于这样一个快速发展的领域来说也是如此。为了保持内容的简洁,我决定今年专注于LLM研究。但即便如此,如何从如此多事的年份中选择一部分论文呢?我想到的最简单的方法是每个月突出一篇论文:从2024年1月到12月。
因此,在这篇文章中,我将分享一些我个人认为引人入胜、有影响力,或者理想情况下,二者兼具的研究论文。然
新年快乐,祝您阅读愉快!
1. 一月:Mixtral的专家混合方法
仅仅在2024年1月的几天内,Mistral AI团队分享了专家混合模型论文(2024年1月8日),该论文描述了Mixtral 8x7B,一个稀疏专家混合模型(SMoE)。
这篇论文和模型在当时都非常有影响力,因为Mixtral 8x7B是(其中之一)首个开放权重的MoE大型语言模型,其表现令人印象深刻:在各种基准测试中,它超越了Llama 2 70B和GPT-3.5。
1.1 理解MoE模型
MoE,即专家混合模型,是一种集成模型,它结合了多个较小的“专家”子网络,位于类似GPT的解码器架构中。每个子网络被认为负责处理不同类型的任务或更具体地说,是处理不同的标记。其核心思想是,通过使用多个较小的子网络而不是一个大型网络,MoE旨在更有效地分配计算资源。
具体来说,在Mixtral 8x7B中,目的是用8个专家层替换变换器架构中的每个前馈模块,如下图所示。
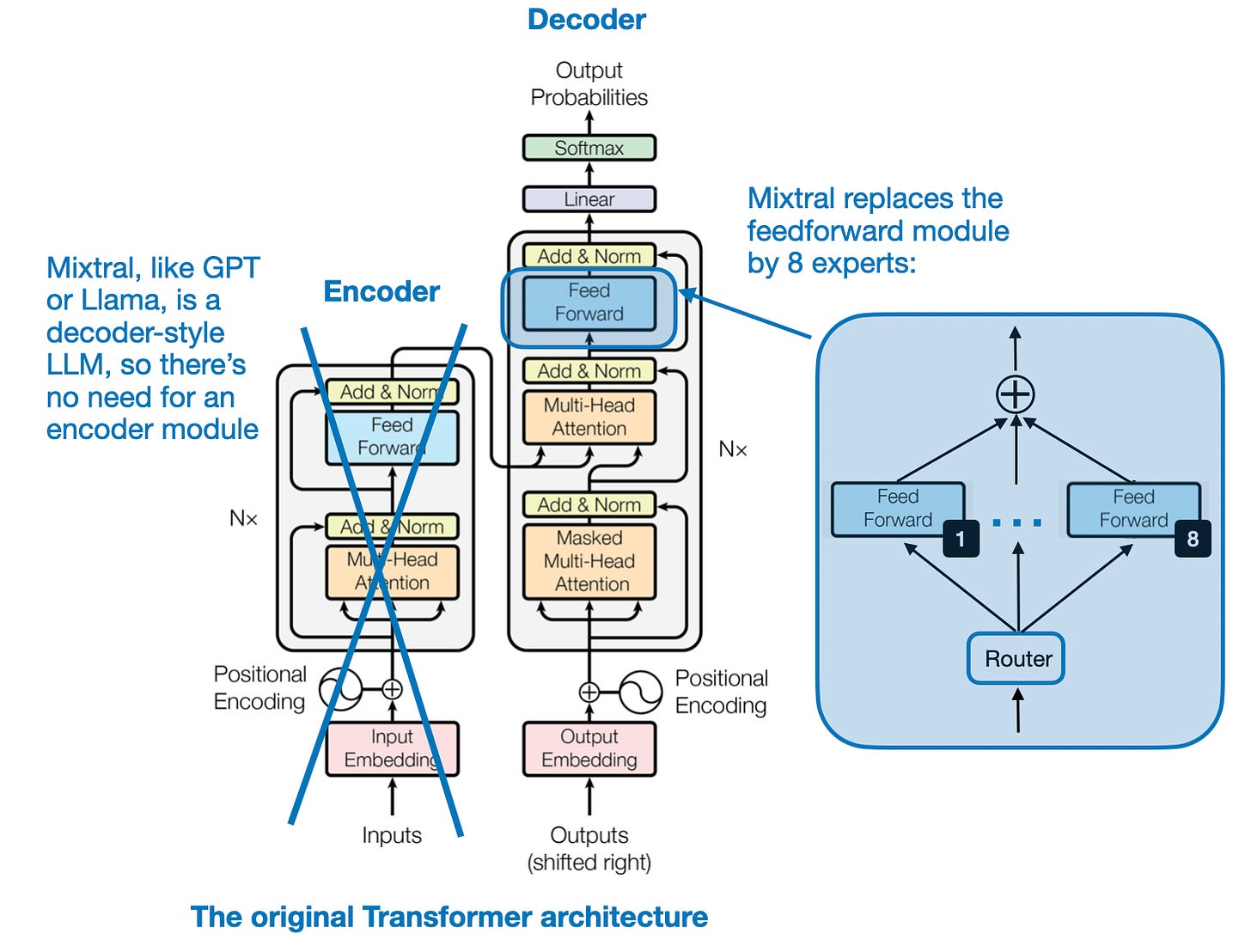
来自《Attention Is All You Need》的注释变换器架构,https://arxiv.org/abs/1706.03762
在“稀疏专家混合模型”的背景下,“稀疏”指的是在任何给定时刻,仅有一部分专家层(通常是Mixtral 8x7B中的1或2个)被用于处理一个标记。
如上图所示,子网络替代了LLM中的前馈模块。前馈模块本质上是一个多层感知器。在类似PyTorch的伪代码中,它的基本结构如下:
class FeedForward(torch.nn.Module):
def __init__(self, embed_dim, coef):
super().__init__()
self.layers = nn.Sequential(
torch.nn.Linear(embed_dim, coef*embed_dim),
torch.nn.ReLU(),
torch.nn.Linear(coef*n_embed, embed_dim),
torch.nn.Dropout(dropout)
)
def forward(self, x):
return self.layers(x)
此外,还有一个 Router 模块(也称为 gating network),它将每个令牌嵌入重定向到 8 个专家前馈模块中,其中只有一部分专家在某一时刻处于激活状态。
由于本文还有 11 篇论文需要介绍,我想简要描述一下 Mixtral 模型。不过,您可以在我之前的文章中找到更多细节, 模型合并、专家混合与更小的 LLM。
1.2 当前 MoE 模型的相关性
年初时,我曾认为开放权重的 MoE 模型会比现在更受欢迎和广泛使用。虽然它们并非无关紧要,但许多最先进的模型仍然依赖于稠密(传统)LLM,而非 MoE,例如 Llama 3、Qwen 2.5、Gemma 2 等。然而,当然无法确定像 GPT-4、Gemini 和 Claude 这样的专有架构是基于什么;它们也可能在底层使用 MoE。
无论如何,MoE 架构仍然相关,特别是因为它们提供了一种有效扩展大型语言模型的方法,通过仅为每个输入激活模型参数的一个子集,从而降低计算成本而不牺牲模型容量。
顺便提一下,在撰写本文后,12 月份发布了一个表现非常优秀的 DeepSeek-V3 模型,它使用了 MoE 架构。因此,是的,MoE 仍然非常相关!
2. 二月:权重分解的 LoRA
如果您正在微调开放权重的 LLM,您很可能在某个时刻使用过低秩适配(LoRA),这是一种参数高效的 LLM 微调方法。
如果你对LoRA不太熟悉,我之前写过一篇关于使用LoRA(低秩适应)微调大型语言模型的实用技巧的文章,你可能会觉得有帮助。此外,我在我的书从零开始构建大型语言模型的附录D中提供了从头开始的代码实现。
由于LoRA是一种非常流行且广泛使用的方法,而我在实现和玩弄一个更新变体时也乐在其中,因此我在二月份推荐的文章是刘及其同事的DoRA:权重分解低秩适应(2024年2月)。
2.2 LoRA回顾
在介绍DoRA之前,这里有一个快速的LoRA回顾:
完全微调通过计算一个大的权重更新矩阵ΔW来更新LLM中的每个大型权重矩阵W。LoRA将ΔW近似为两个较小矩阵A和B的乘积。因此,我们有W + A.B,而不是W + ΔW。这大大减少了计算和内存开销。
下图并排展示了完全微调(左)和LoRA(右)的公式。
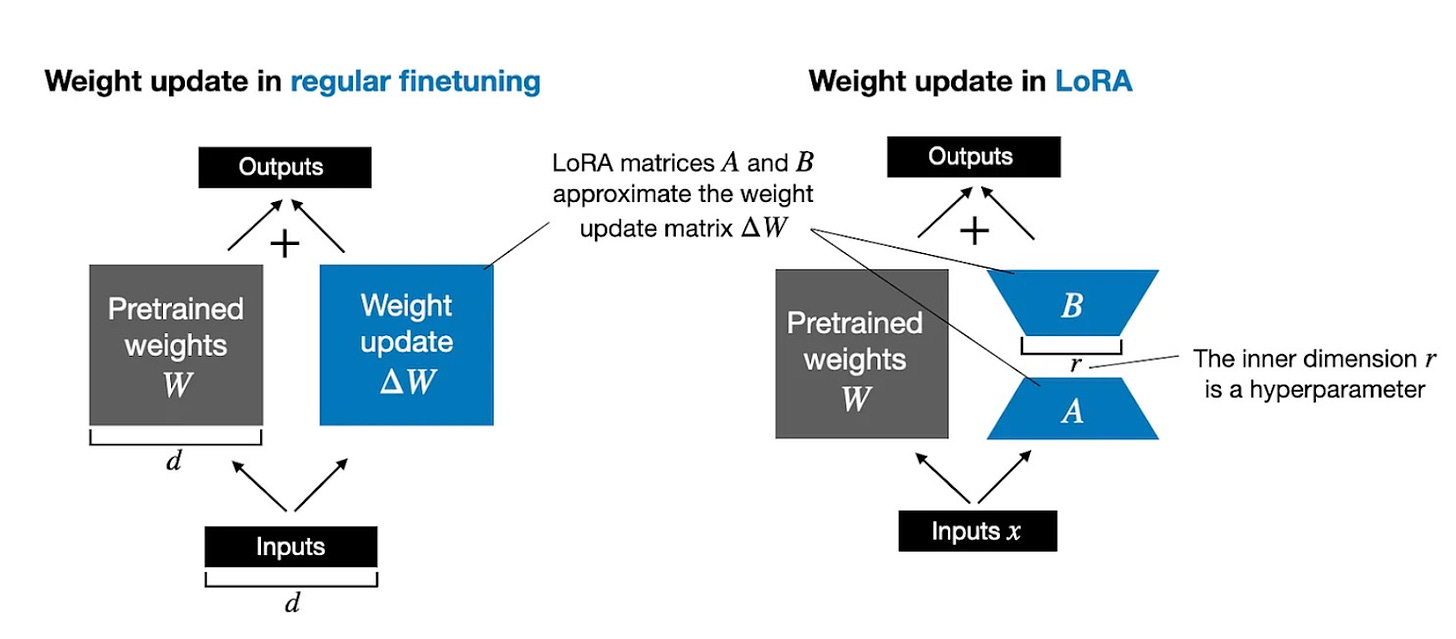
常规微调(左)和LoRA微调(右)的示意图。
2.2 从LoRA到DoRA
在DoRA: 权重分解低秩适应(2024年2月),Liu及其同事通过首先将预训练的权重矩阵分解为两个部分:一个幅度向量m和一个方向矩阵V,扩展了LoRA。这种分解的基础在于任何向量都可以通过其长度(幅度)和方向(取向)来表示,在这里我们将其应用于权重矩阵的每一列向量。一旦我们得到了m和V,DoRA仅对方向矩阵V应用LoRA风格的低秩更新,同时允许幅度向量m单独进行训练。
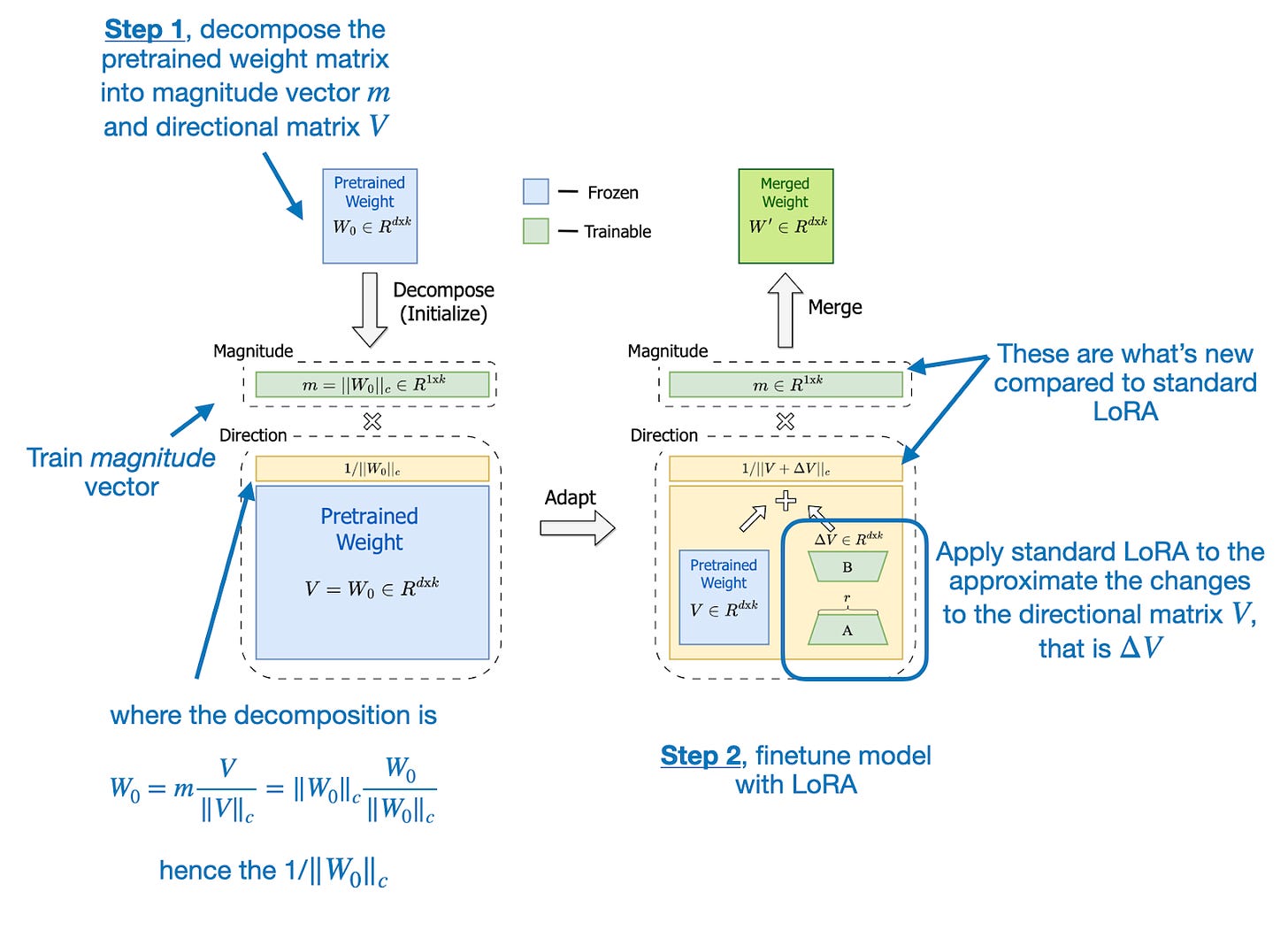
来自DoRA论文的注释插图 (https://arxiv.org/abs/2402.09353)
这种两步法使DoRA比标准的LoRA更具灵活性。与LoRA倾向于均匀缩放幅度和方向不同,DoRA可以在不必增加幅度的情况下进行微妙的方向调整。结果是性能和鲁棒性的提升,因为即使在使用更少参数的情况下,DoRA也能超越LoRA,并且对秩的选择不那么敏感。
再次强调,由于还有10个部分要介绍,我将这一部分保持简短,但如果您对更多细节感兴趣,我在今年早些时候专门撰写了一篇关于该方法的文章:改进LoRA:从零开始实现权重分解低秩适应(DoRA)。
2.3 LoRA及类似方法的未来
DoRA 是对原始 LoRA 方法的小幅逻辑改进。尽管它尚未被广泛采用,但它增加的复杂性极小,值得在下次微调 LLM 时考虑。一般来说,我预计 LoRA 和类似的方法将继续保持受欢迎。例如,苹果最近在他们的 Apple Intelligence Foundation Language Models 论文中提到,他们使用 LoRA 来实现 LLM 的设备内任务专业化。
3. 三月:持续预训练 LLM 的技巧
据我所知,指令微调是 LLM 从业者中最流行的微调形式。其目标是使公开可用的 LLM 更好地遵循指令,或使这些 LLM 在子集或新指令上进行专业化。
然而,当涉及到获取新知识时,持续预训练(有时也称为不断预训练)是最佳选择。
在本节中,我想简要总结 Ibrahim 和同事们的论文 Simple and Scalable Strategies to Continually Pre-train Large Language Models(2024年3月),这篇论文内容清晰明了。
3.1 简单技巧有效
这篇 24 页的 Continually Pre-train Large Language Models 论文报告了大量实验,并附有无数图表,符合当今的标准,非常详尽。
成功应用持续预训练的主要建议是什么?
-
简单的重新升温和重新衰减学习率。
-
向新数据集中添加一小部分(例如,5%)原始预训练数据,以防止灾难性遗忘。请注意,像 0.5% 和 1% 这样的小比例也有效。 为了更具体地说明第一点,重新加热和重新衰减,这意味着我们采用与LLM初始预训练阶段相同的学习率调度,如下图所示。
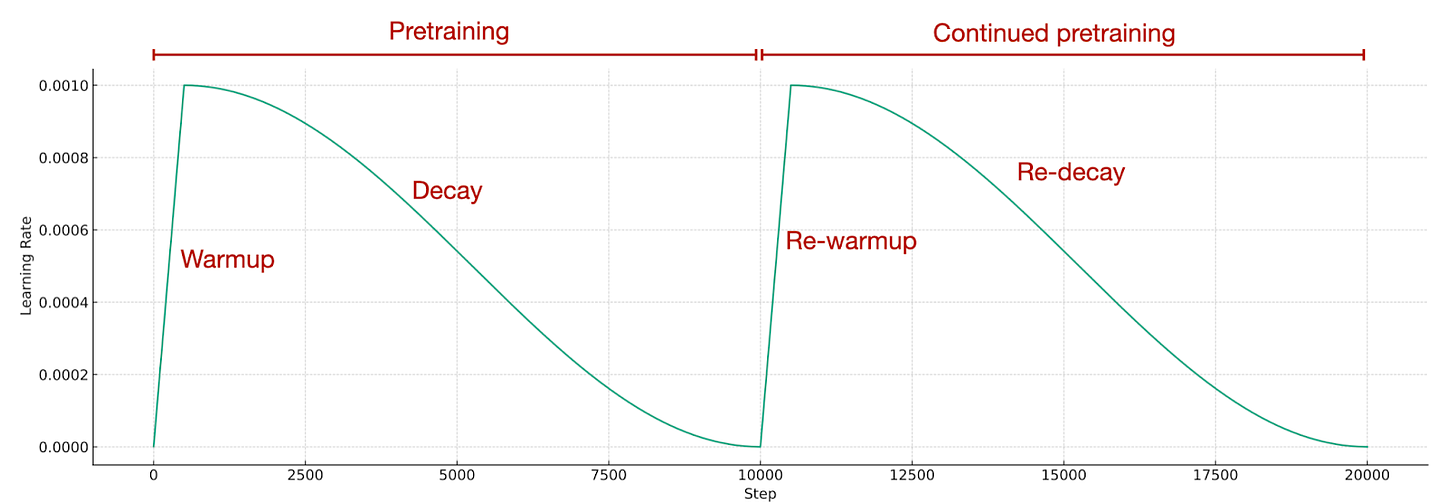
继续预训练的调度。图基于《从头开始构建大型语言模型》,https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-D/01_main-chapter-code/appendix-D.ipynb
据我所知,重新加热和重新衰减,以及将原始预训练数据添加到新数据中,或多或少是常识。然而,我非常感谢研究人员花时间在这份详细的24页报告中正式测试这种方法。
如果您对更多细节感兴趣,我在之前的LLM预训练和评估奖励模型的技巧文章中更深入地讨论了这篇论文。
3.2 这些简单的技术会继续有效吗?
我没有理由相信这些方法不会继续适用于未来的LLM。然而,重要的是要注意,预训练管道在最近几个月变得更加复杂,包含多个阶段,包括短期和长期上下文的预训练。(我在新的LLM预训练和后训练范式中写了更多内容)。
因此,为了获得最佳结果,本文中建议的方案在某些情况下可能需要进行调整。
4. 四月:DPO还是PPO用于LLM对齐,或者两者都用?
四月是一个艰难的选择。例如,Kolmogorov-Arnold 网络 在那个时候引起了很大的关注。但据我所知,这种兴奋感很快就消退了。这可能是因为它们的理论保证在实际应用中难以实现,缺乏竞争性的结果或基准,且其他架构的可扩展性更强。
因此,我在四月的选择更倾向于一篇更实用的论文:DPO 是否优于 PPO 用于 LLM 对齐?一项综合研究(2024年4月),作者是徐及其同事。
4.1 RLHF-PPO 和 DPO:它们是什么?
在总结论文本身之前,先来概述一下近端策略优化(PPO)和直接偏好优化(DPO),这两种方法在通过人类反馈的强化学习(RLHF)对 LLM 进行对齐时非常流行。RLHF 是对齐 LLM 与人类偏好的首选方法,旨在提高其响应的质量和安全性。

典型的(简化的)LLM 训练生命周期。
传统上,RLHF-PPO 一直是训练 LLM 的关键步骤,适用于 InstructGPT 和 ChatGPT 等模型和平台。然而,由于其简单性和有效性,DPO 去年开始受到关注。与 RLHF-PPO 相比,DPO 不需要单独的奖励模型。相反,它使用类似分类的目标直接更新 LLM。许多 LLM 现在都采用 DPO,尽管与 PPO 的全面比较仍然缺乏。
以下是我在今年早些时候开发并分享的关于 RLHF 和 DPO 的两个资源:
4.2 PPO通常优于DPO
直接偏好优化是否优于PPO用于LLM对齐?一项综合研究 是一篇写得很好的论文,包含了大量实验和结果。主要结论是PPO往往优于DPO,并且在处理分布外数据时,DPO表现较差。
这里的分布外数据是指语言模型之前在与DPO使用的偏好数据不同的指令数据上进行训练(通过监督微调)。例如,一个模型可能在通用的Alpaca数据集上进行训练,然后在不同的偏好标记数据集上进行DPO微调。(然而,改善DPO在此类分布外数据上的一种方法是,首先使用偏好数据集进行监督指令微调,然后再进行DPO微调。)
主要发现总结在下面的图中。
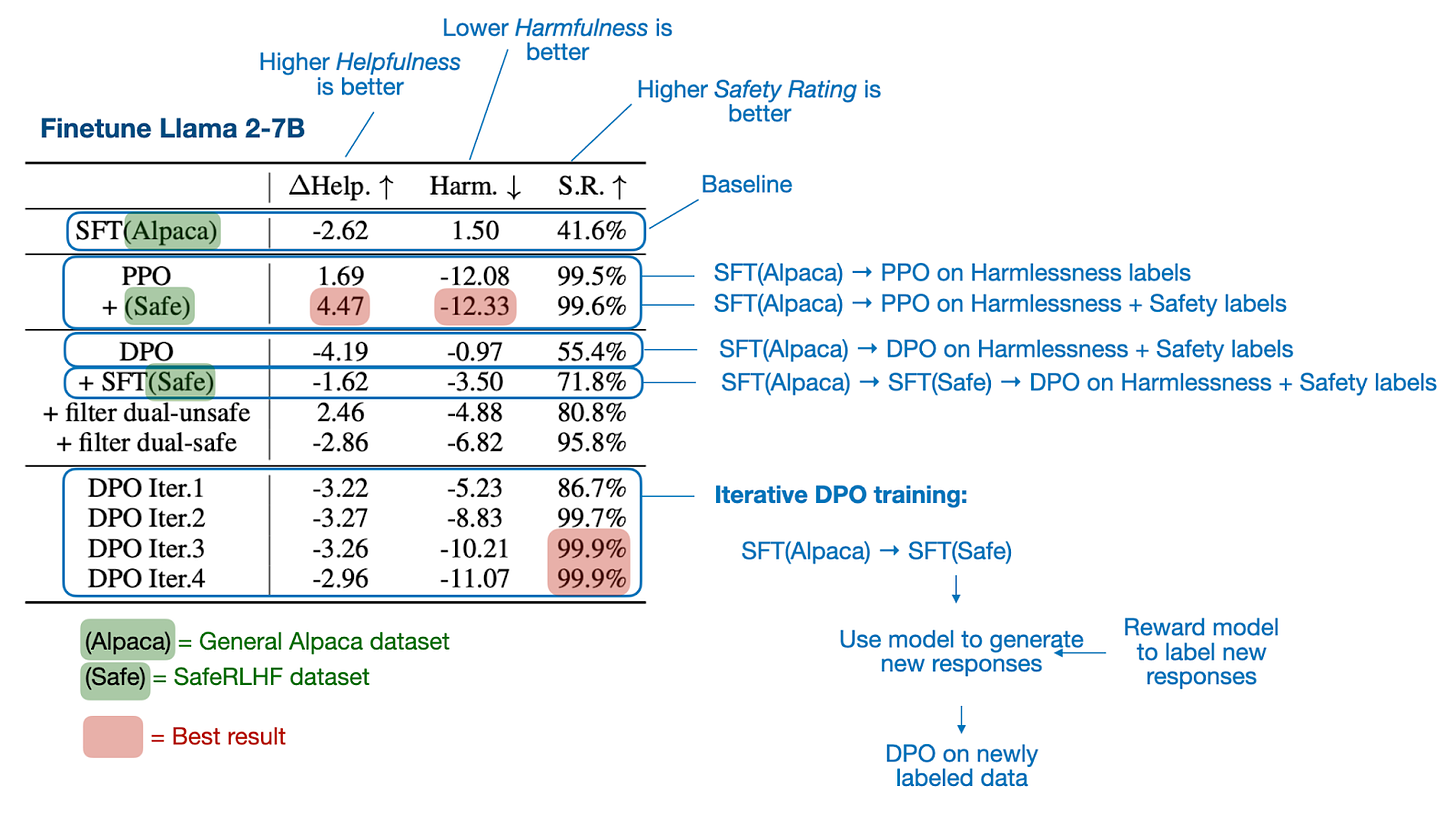
来自《直接偏好优化是否优于PPO用于LLM对齐?一项综合研究》(https://arxiv.org/abs/2404.10719)论文的注释表。
4.3 PPO和DPO今天是如何使用的?
PPO在生成的LLM的原始建模性能上可能略有优势。然而,DPO的实现要简单得多,计算效率也更高(毕竟你不需要训练和使用单独的奖励模型)。因此,据我所知,DPO在实际应用中也比RLHF-PPO更为广泛。
一个有趣的例子是Meta AI的Llama模型。虽然Llama 2是通过RLHF-PPO训练的,但更新的Llama 3模型则使用了DPO。
有趣的是,最近的模型甚至同时使用PPO和DPO。最近的例子包括苹果的基础模型和Allen AI的Tulu 3。
5. 五月:LoRA学习更少且遗忘更少
我发现今年的另一篇LoRA论文特别有趣(这是我承诺的这12篇论文中最后一篇LoRA论文!)。我不会称其为突破性,但我真的很喜欢它,因为它对使用(和不使用)LoRA微调LLM的一些常识进行了形式化:LoRA学习更少且遗忘更少(2024年5月)由Biderman及其同事撰写。
LoRA学习更少且遗忘更少是一项实证研究,比较了低秩适应(LoRA)与大型语言模型(LLMs)的完全微调,重点关注两个领域(编程和数学)和两个任务(指令微调和持续预训练)。如果你想在继续之前复习一下LoRA,请查看上面的二月部分。
5.1 LoRA学习更少
LoRA 学习更少且遗忘更少 的研究表明,LoRA 的学习能力明显低于完全微调,尤其是在需要获取新知识的任务中,如编码。当仅进行指令微调时,这一差距会缩小。这表明,在新数据上进行预训练(学习新知识)比将预训练模型转换为指令跟随者更能从完全微调中受益。
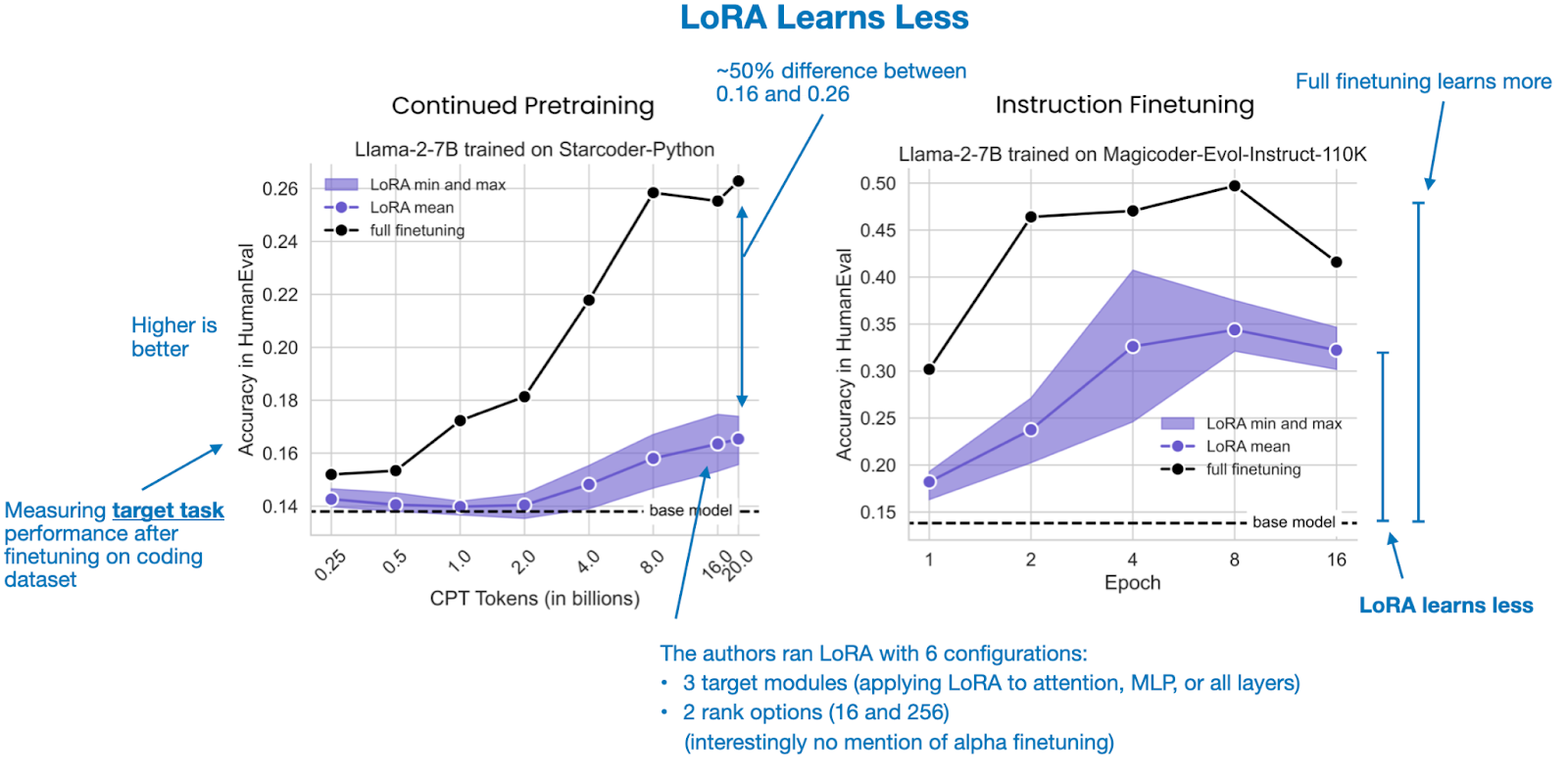。](https://p.ipic.vip/20w3rn.png)
不过,还有一些更细微的差别。例如,对于数学任务,LoRA 和完全微调之间的差距缩小。这可能是因为数学问题对 LLM 来说更为熟悉,它们在预训练期间可能遇到过类似的问题。相比之下,编码涉及一个更为独特的领域,需要更多的新知识。因此,新任务与模型的预训练数据相距越远,完全微调在学习能力方面的益处就越明显。
5.2 LoRA 遗忘更少
当考察之前获得的知识损失程度时,LoRA 一直表现出较少的遗忘。这一点在适应与源领域相距较远的数据时尤为明显(例如,编程)。在编程任务中,完全微调会导致显著的遗忘,而 LoRA 则能保留更多的原始能力。在数学领域,由于模型的原始知识与新任务已经较为接近,因此差异不那么明显。
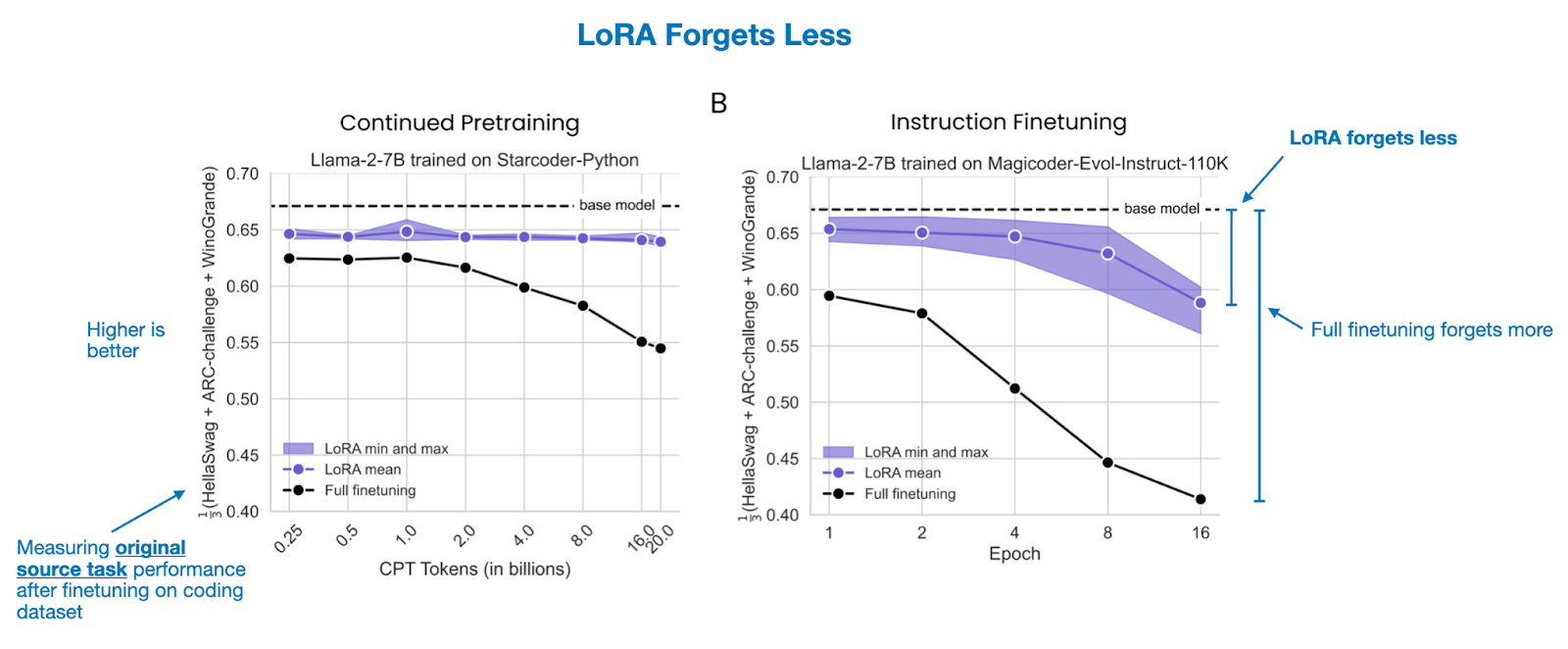
在编程数据训练后,完全微调与 LoRA 在原始源任务上的表现。图示来自《LoRA 学得更少且遗忘更少》,阅读更多。
5.3 LoRA 权衡
总体而言,这是一种权衡:完全微调更适合从更远的领域吸收新知识,但会导致对之前学习任务的更多遗忘。LoRA 通过调整更少的参数,学习到的新信息较少,但能保留更多的原始能力。
5.4 微调 LLMs 的未来方法
该研究主要将LoRA与完全微调进行比较。在实际应用中,LoRA因其比完全微调更具资源效率而受到广泛欢迎。在许多情况下,由于硬件限制,完全微调根本不可行。此外,如果您只需要处理特定应用,单独使用LoRA可能就足够了。由于LoRA适配器可以与基础LLM分开存储,因此在添加新功能的同时,保留原有能力变得简单。此外,可以通过对知识更新使用完全微调,而对后续专业化使用LoRA来结合这两种方法。
简而言之,我认为这两种方法在未来一年内仍将非常相关。关键在于为手头的任务选择合适的方法。
6. 六月:15万亿标记的FineWeb数据集
Penedo及其同事的论文《FineWeb数据集:大规模提取网络中最优文本数据》(2024年6月)描述了为LLM创建一个15万亿标记的数据集并将其公开发布的过程,包括下载数据集的链接和一个代码库(datatrove/examples/fineweb.py),用于重现数据集准备步骤。
6.1 与其他数据集的比较
由于还有其他几个大型数据集可用于LLM预训练,那么这个数据集有什么特别之处呢?其他数据集相对较小:RefinedWeb(5000亿标记)、C4(1720亿标记)、Dolma 1.6(基于Common Crawl的部分,3万亿标记)和1.7(1.2万亿标记)、The Pile(340亿标记)、SlimPajama(627亿标记)、RedPajama的去重变体(2万亿标记)、Matrix的英语CommonCrawl部分(1.3万亿标记)、英语CC-100(700亿标记)、Colossal-OSCAR(850亿标记)。
例如,约3600亿个标记仅适合小型LLM(例如,根据Chinchilla缩放法则的1.7B)。另一方面,FineWeb数据集中包含的15万亿个标记根据Chinchilla缩放法则应该是适合最多5000亿参数模型的最佳选择。(注意,RedPajama包含20万亿个标记,但研究人员发现,由于应用了不同的过滤规则,基于RedPajama训练的模型质量低于FineWeb。)
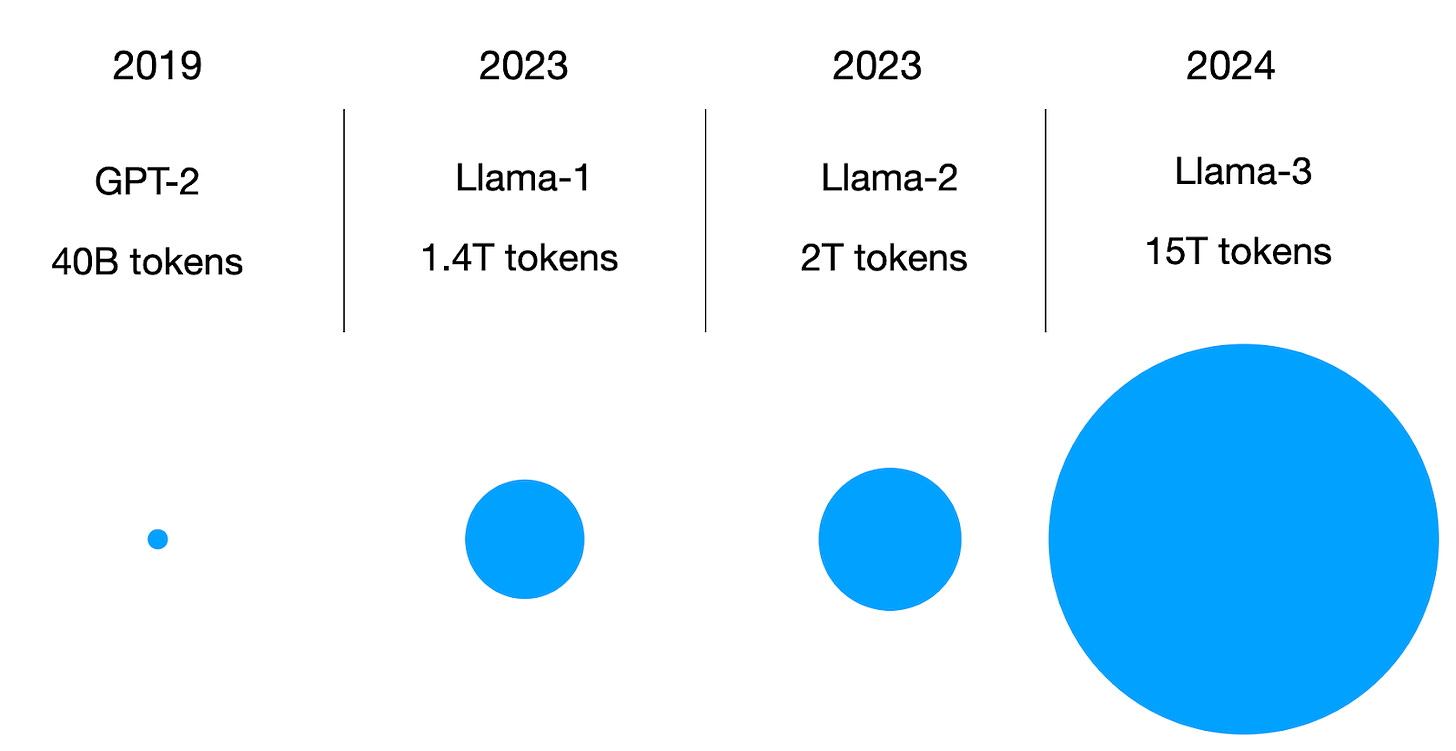
用于预训练LLM的数据集规模示意图。请注意,这仅是一个一般参考,与FineWeb论文或Chinchilla缩放法则论文没有直接关系。
简而言之,FineWeb数据集(仅限英语)在理论上使研究人员和从业者能够训练大规模LLM。(附注:Llama 3模型的8B、70B和405B大小也在15万亿个标记上进行训练,但Meta AI的训练数据集并未公开。)
6.2 原则性数据集开发
此外,本文包含了原则性的消融研究以及关于过滤规则如何开发和应用以形成FineWeb数据集的见解(该数据集起源于CommonCrawl网络语料库)。简而言之,对于他们尝试的每个过滤规则,他们从原始数据和过滤后的数据中随机抽取了3600亿个标记样本,然后训练了一个小型的17.1亿参数的类似Llama的模型,以根据模型在标准基准(如HellaSwag、ARC、MMLU等)上的表现来判断该过滤规则是否有益。
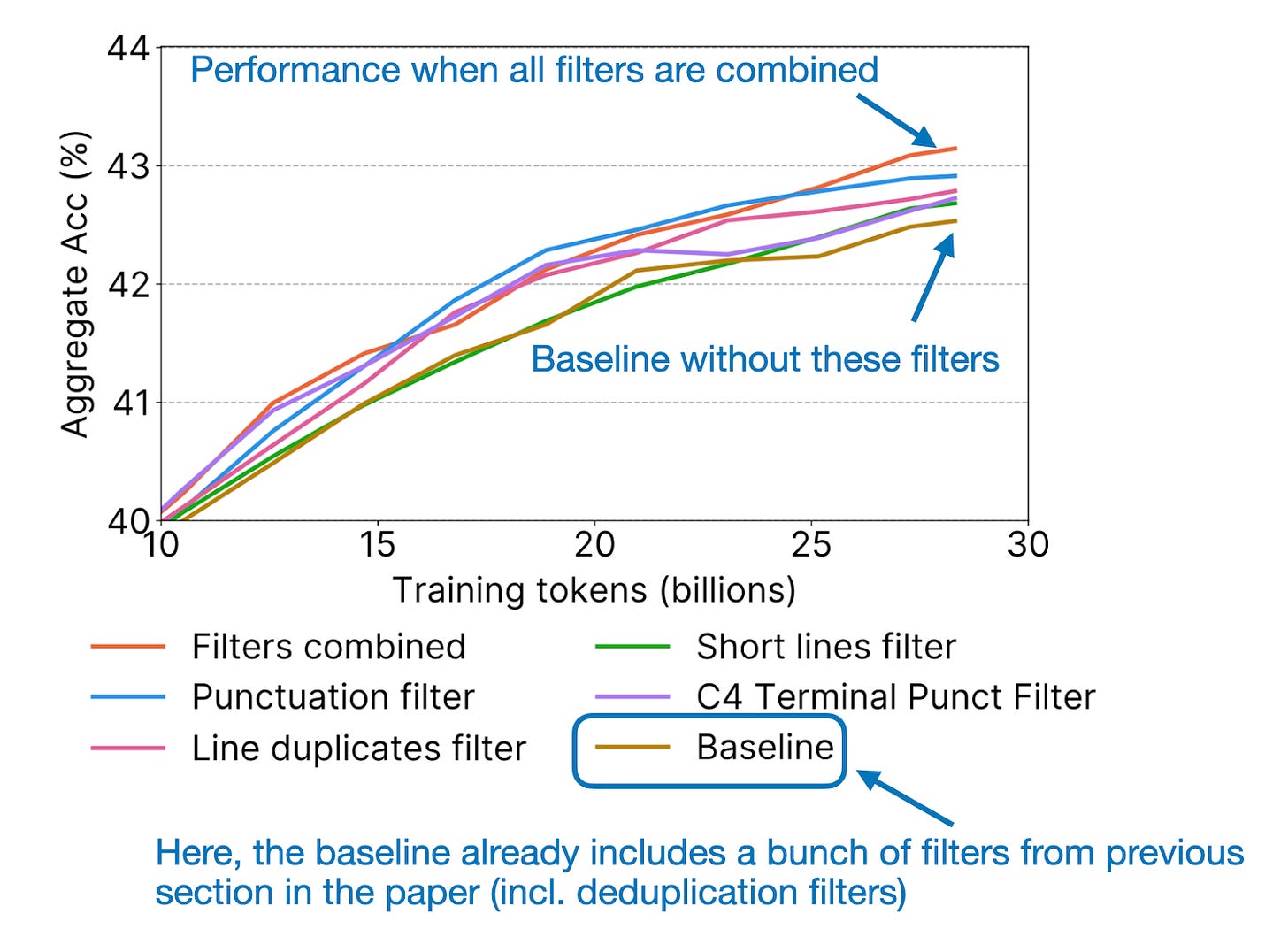
6.3 FineWeb的当今相关性
总体而言,尽管预训练数十亿参数的LLM仍然超出了大多数研究实验室和公司的能力范围,但这个数据集是朝着民主化LLM研究和开发迈出的重要一步。总之,本文代表了一项值得称赞的努力,并为推动LLM的预训练引入了一个有价值的公共资源。
7. 七月:Llama 3模型家族
读者们可能已经对Meta AI的Llama 3模型及其论文非常熟悉,但由于这些模型如此重要且广泛使用,我想将七月的部分专门献给Grattafiori及其同事的论文《Llama 3模型家族》(2024年7月)。
Llama 3模型家族的显著特点是与其前身Llama 2相比,预训练和后训练流程的复杂性有所增加。请注意,这不仅适用于Llama 3,还适用于其他LLM,如Gemma 2、Qwen 2、苹果的基础模型等,正如我几个月前在我的文章《新的LLM预训练和后训练范式》中所描述的那样。
7.1 Llama 3架构总结
Llama 3首次发布时有80亿和700亿参数的版本,但团队不断对模型进行迭代,发布了Llama 3.1、3.2和3.3版本。各版本的参数规模总结如下:
Llama 3(2024年4月)
-
80亿参数
-
700亿参数 Llama 3.1(2024年7月,论文中讨论)
-
8B 参数
-
70B 参数
-
405B 参数
Llama 3.2(2024年9月)
-
1B 参数
-
3B 参数
-
11B 参数(支持视觉)
-
90B 参数(支持视觉)
Llama 3.3(2024年12月)
- 70B 参数
总体而言,Llama 3 的架构与 Llama 2 非常相似。主要区别在于其更大的词汇量以及为较小模型变体引入的分组查询注意力。下图展示了这些差异的总结。
如果你对架构细节感兴趣,一个很好的学习方式是从头实现模型,并加载预训练权重作为合理性检查。我有一个 GitHub 仓库,里面有从头实现的代码,可以将 GPT-2 转换为 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2。
7.3 Llama 3 训练
另一个值得注意的更新是,Llama 3 现在已经在 15 万亿个标记上进行了训练。
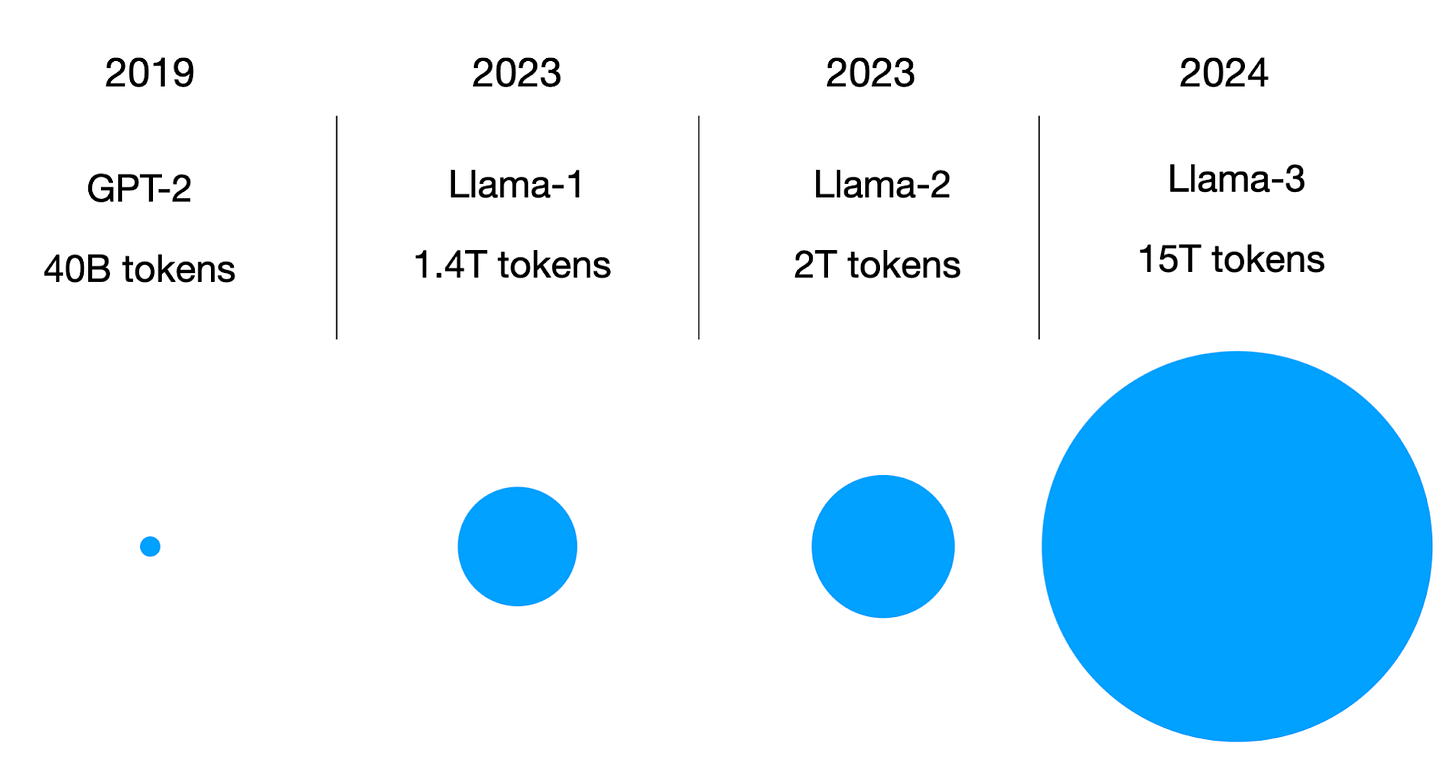
各种模型训练集大小的比较。
预训练过程现在是多阶段的。论文主要集中在 Llama 3.1,为了简洁起见,我在下图中总结了其预训练技术。
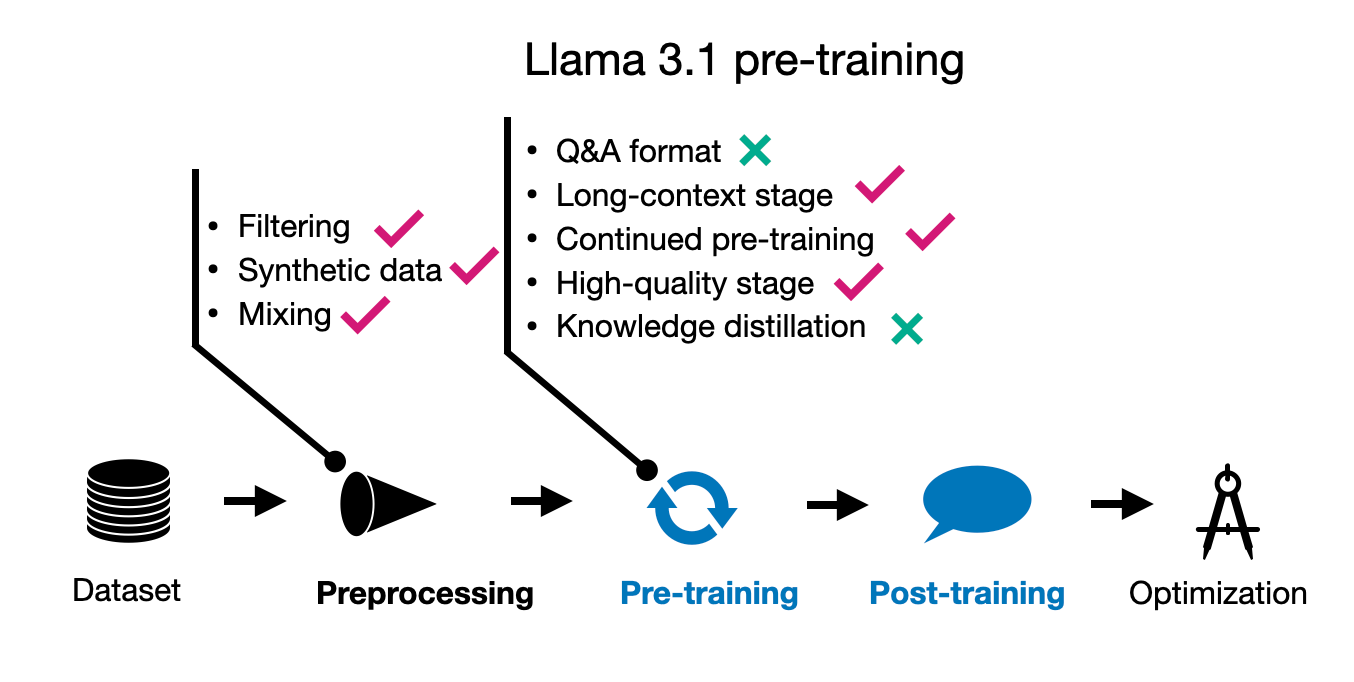
Llama 3.1 预训练中使用的技术总结。 在后训练阶段,Llama 2 的一个显著变化是从 RLHF-PPO 切换到 DPO。这些方法在下面的图中也进行了总结。
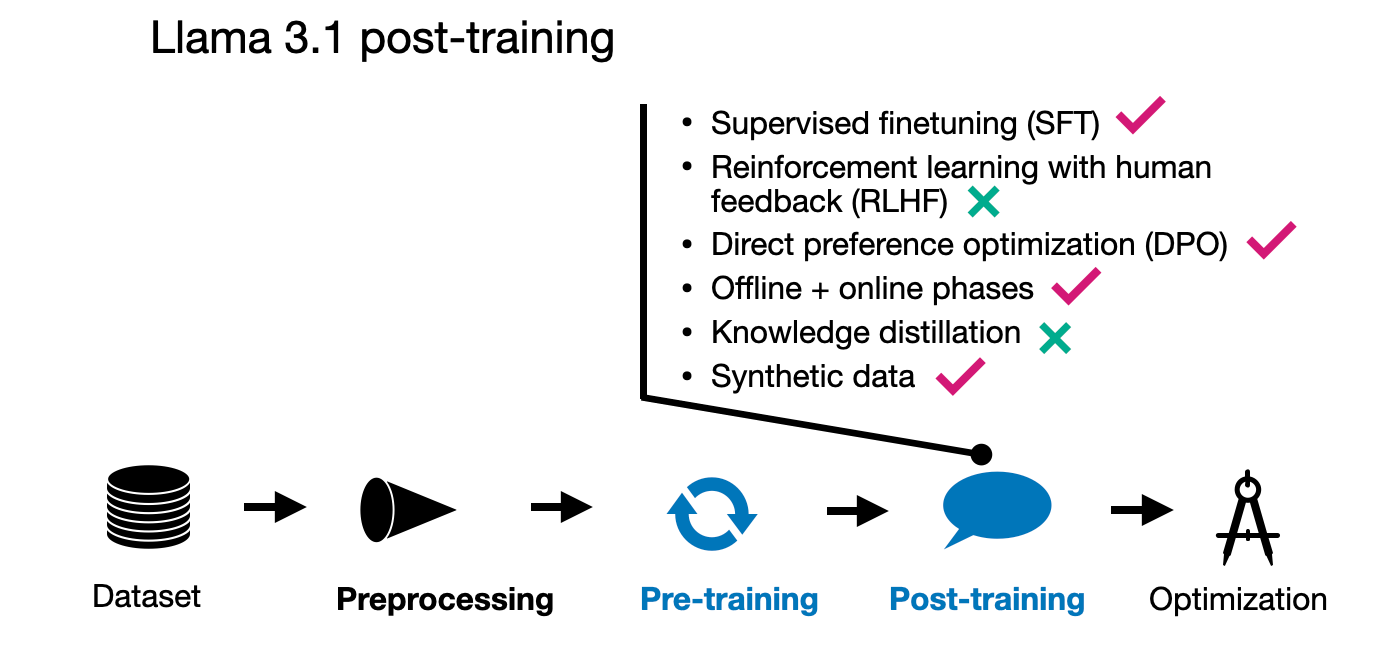
为了简洁起见,由于本文还需涵盖另外五篇论文,我将把额外的细节和与其他模型的比较推迟到我之前的一篇文章中。新的 LLM 预训练和后训练范式。
7.4 多模态 Llama
请注意,Llama 3.2 模型也已发布,支持多模态。然而,我并未观察到这些模型在实际中的广泛使用,且讨论也不多。我们将在本文后面的九月部分重新审视多模态技术。
7.5 Llama 3 的影响和使用
尽管 Llama 3 发布已经超过半年,但 Llama 模型仍然是最广为人知和使用的开放权重 LLM 之一(基于我的个人感知,因为我没有具体的来源可供引用)。这些模型相对容易理解和使用。它们受欢迎的原因可能在于 Llama 品牌的认知度,加上在各种通用任务中的强大表现,以及便于微调的特性。
Meta AI 也通过对 Llama 3 模型的迭代保持了势头,发布了 3.1、3.2 和现在的 3.3 版本,这些版本涵盖了多种规模,以满足从设备端场景(1B)到高性能应用(400B)的多样化使用案例。 尽管该领域现在包括许多竞争激烈的开源和开放权重的大型语言模型(LLM),如 Olmo 2、Qwen 2.5、Gemma 2 和 Phi-4 等,我相信 Llama 将继续成为大多数用户的首选模型,就像 ChatGPT 尽管面临 Anthropic Claude、Google Gemini、DeepSeek 等选项的竞争,仍然保持其受欢迎程度一样。
就我个人而言,我对 Llama 4 感到兴奋,希望它能在 2025 年某个时候发布。
8. 八月:通过扩展推理时计算来改善 LLM
我本月的推荐是 优化 LLM 测试时计算的扩展比扩展模型参数更有效(2024 年 8 月),因为这是一篇写得非常好且详细的论文,提供了一些有趣的见解,关于如何在推理时(即部署)改善 LLM 的响应。
8.1 通过增加测试时计算来改善输出
本文的主要前提是研究增加测试时计算是否以及如何能够改善 LLM 的输出。粗略类比一下,假设人类在面对困难任务时,如果给他们更多的思考时间,可以生成更好的回应。类似地,LLM 可能在生成响应时,如果有更多的时间/资源,能够产生更好的输出。从更技术的角度来看,研究人员试图找出在推理过程中使用额外计算时,模型的表现能比训练时更好多少。
此外,研究人员还探讨了在固定计算预算下,增加测试时计算是否能改善结果,相较于将这些计算用于进一步的模型预训练。但关于这一点稍后再说。
8.2 优化测试时计算技术
论文详细描述了提高和优化测试时间计算的技术,如果你认真考虑在实践中部署大型语言模型(例如前面提到的Llama模型),我强烈建议你完整阅读这篇论文。
简而言之,扩展测试时间计算的两种主要方法是:
-
生成多个解决方案,并使用基于过程的验证奖励模型(需要单独训练)来选择最佳响应
-
自适应更新模型的响应分布,这本质上意味着在推理生成过程中修订响应(这也需要一个单独的模型)。
为了提供一个简单的例子,类别1的一个简单方法是使用最佳的N采样。这意味着我们让大型语言模型并行生成多个答案,然后根据验证奖励模型选择最佳答案。最佳的N只是一个例子。多种搜索算法都属于这一类别:束搜索、前瞻搜索和最佳的N,如下图所示。
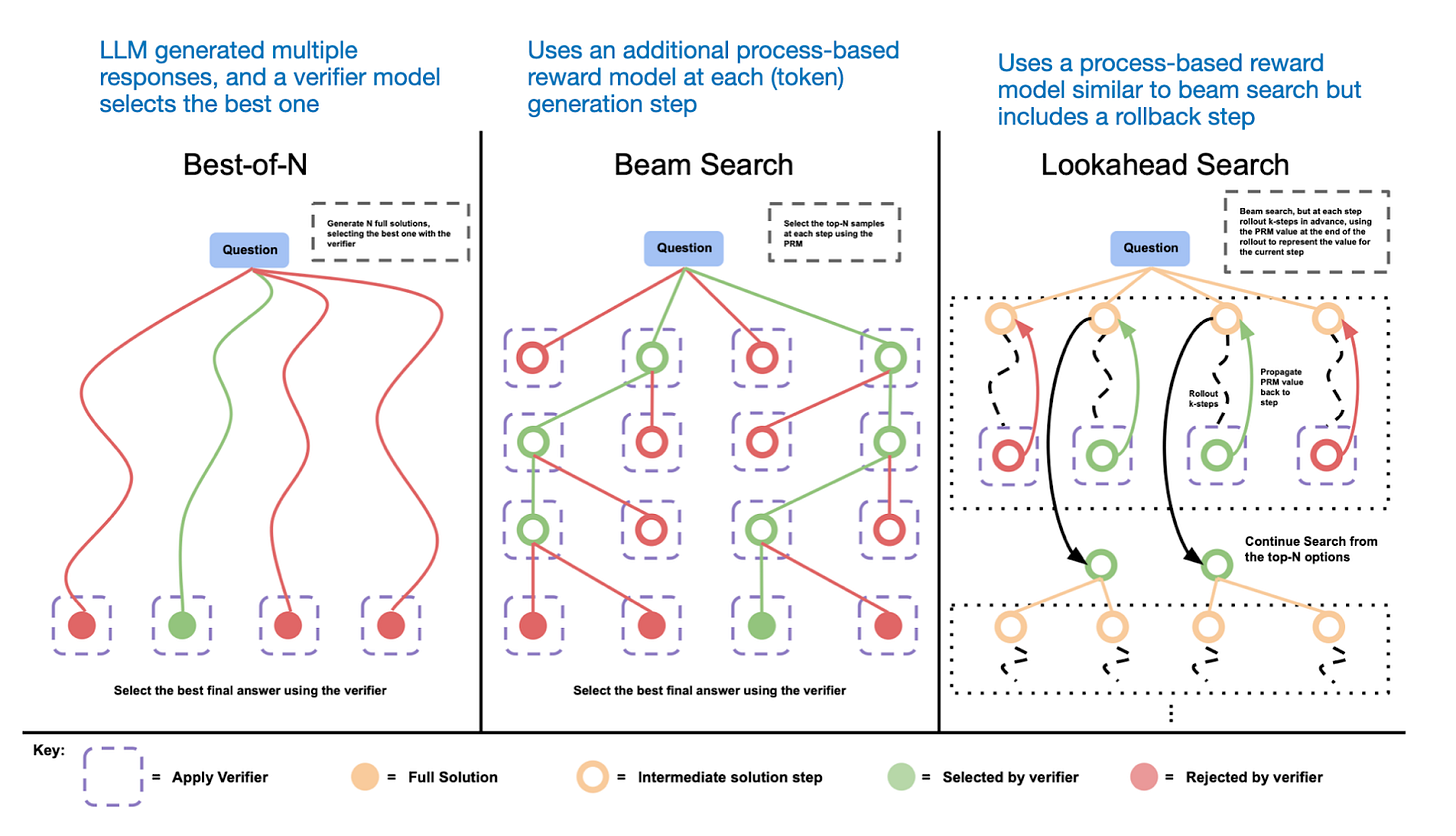
不同的基于搜索的方法依赖于基于过程的奖励模型来选择最佳答案。图示来自LLM测试时间计算论文,https://arxiv.org/abs/2408.03314
另一种方法,属于类别2,是顺序修订模型的响应,如下图所示。
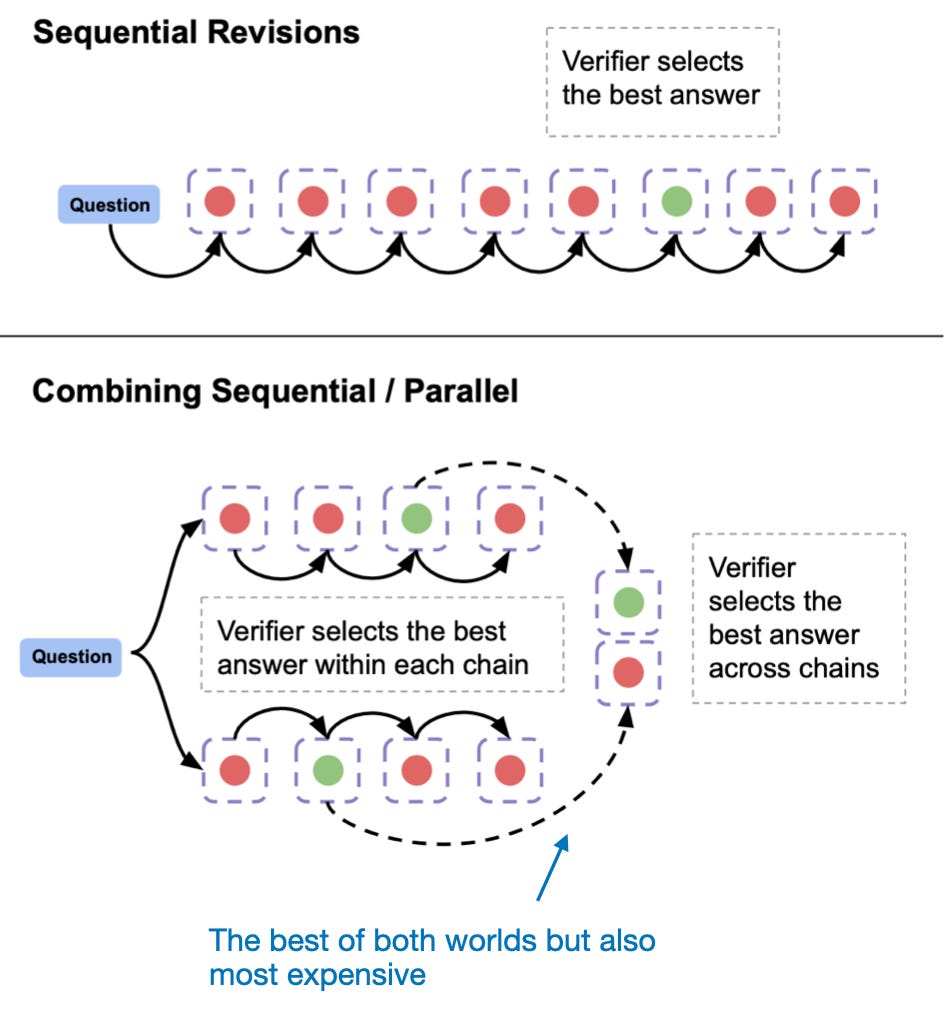
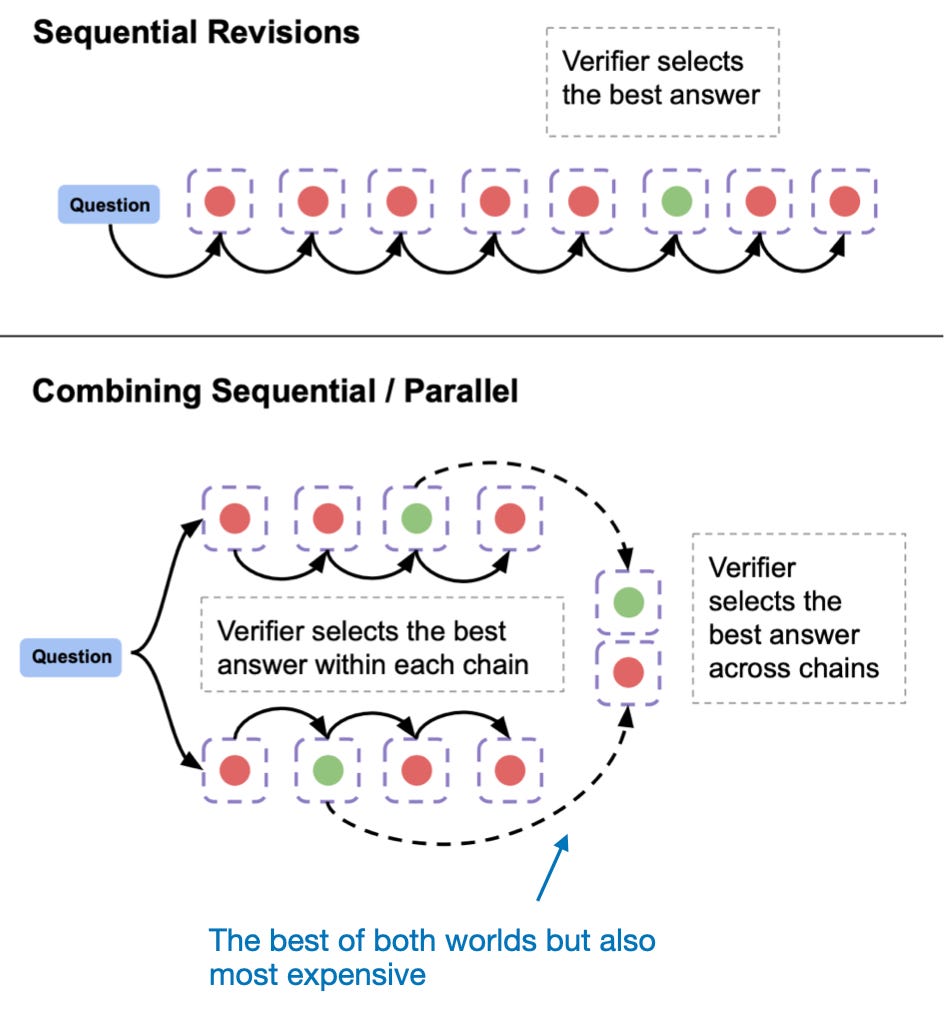
序列修订方法。来自LLM测试时计算论文的注释图,https://arxiv.org/abs/2408.03314
哪种方法效果更好?不幸的是,没有一种通用的答案。这取决于基础的LLM和具体的问题或查询。例如,基于修订的方法在较难的问题上表现更好,而在简单问题上可能会损害性能。
在论文中,他们开发了一种“最佳”策略,该策略基于一个模型来评估查询的难度级别,然后适当地选择正确的策略。
8.3 测试时计算与预训练更大模型的比较
一个有趣的问题是,在固定的计算预算下,什么能带来更大的收益:使用更大的模型还是增加推理时的预算?
在这里,假设你为一个查询支付的价格是相同的,因为在推理中运行大型模型的成本高于小型模型。
他们发现,对于具有挑战性的问题,更大的模型优于通过之前讨论的推理扩展策略获得额外推理计算的小型模型。
然而,对于简单和中等难度的问题,推理时间计算可以用来匹配在相同计算预算下14倍更大模型的性能!
8.4 测试时计算扩展的未来相关性
当使用像 Llama 3 这样的开放权重模型时,我们通常让它们直接生成响应。然而,正如本文所强调的,通过分配更多的推理计算,响应质量可以显著提高。(如果你正在部署模型,这绝对是值得阅读的论文。)
当然,增加大型、昂贵模型的推理计算预算会使其运营成本更高。然而,当根据查询的难度进行选择性应用时,它可以为某些响应提供宝贵的质量和准确性提升,这无疑是大多数用户所欣赏的。(可以安全地假设,OpenAI、Anthropic 和 Google 已经在幕后利用了这样的技术。)
另一个引人注目的用例是提升较小的、设备端 LLM 的性能。我认为这将在未来几个月和几年内继续成为热门话题,正如我们在苹果智能和微软的 Copilot PC 的重大公告和投资中所看到的那样。
9. 九月:比较多模态 LLM 模式
多模态 LLM 是我认为在 2024 年会有重大突破的主要领域之一。是的,今年我们确实获得了一些新的开放权重 LLM!
一个多模态 LLM 的示意图,它可以接受不同的输入模态(音频、文本、图像和视频),并返回文本作为输出模态。
让我特别关注的一篇论文是 NVIDIA 的 NVLM: 开放前沿级多模态 LLM(2024 年 9 月),由 Dai 和同事们撰写,因为它很好地比较了两种领先的多模态模式。
9.1 多模态 LLM 模式
构建多模态 LLM 的主要有两种方法:
-
方法 A:统一嵌入解码器架构;
-
方法 B:跨模态注意力架构。
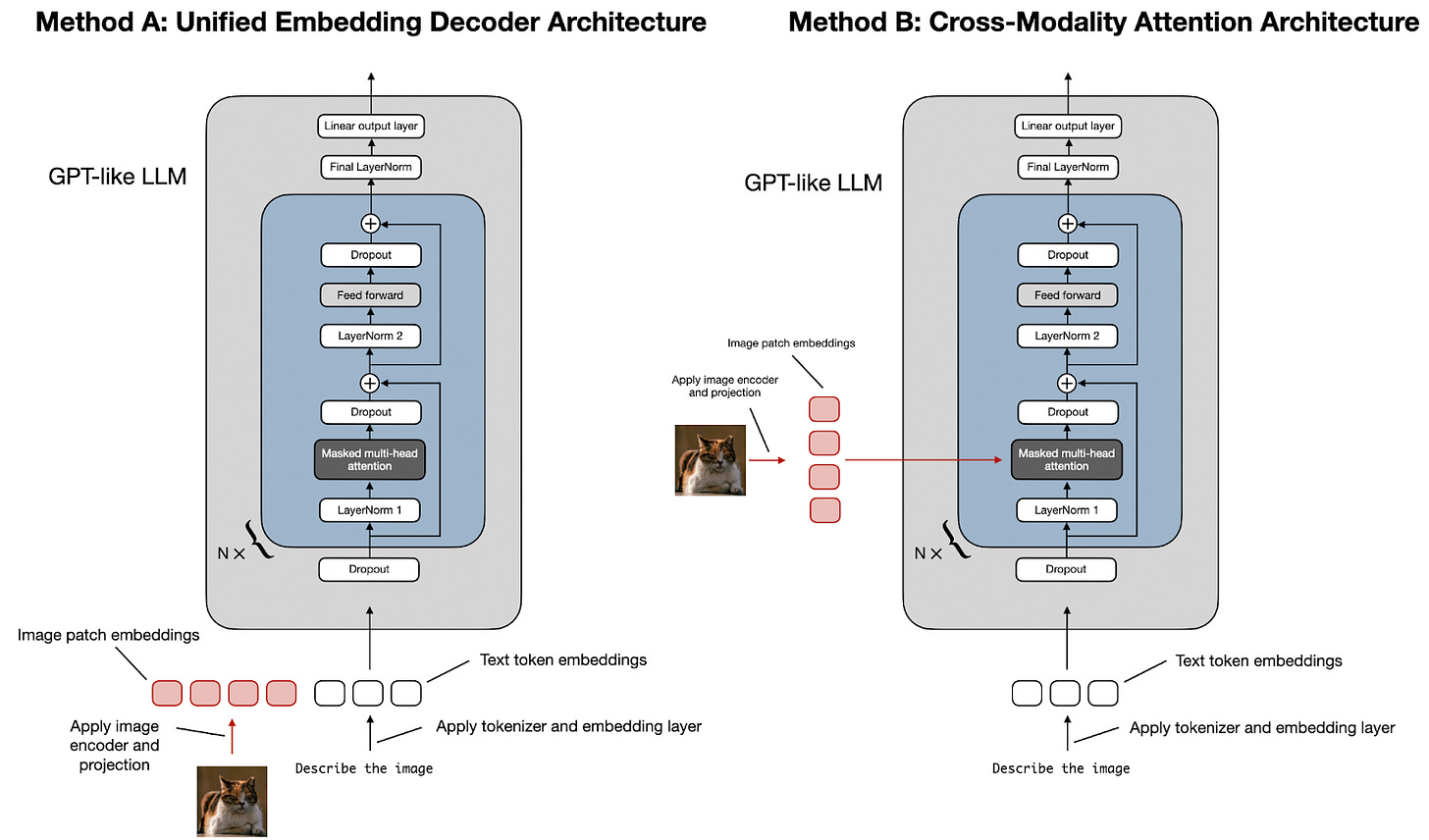
开发多模态 LLM 架构的两种主要方法。
如上图所示,统一嵌入-解码器架构(方法 A)依赖于单一的解码器模型,类似于未修改的 LLM 架构,如 GPT-2 或 Llama 3.2。该方法将图像转换为与文本令牌共享相同嵌入大小的令牌,使得 LLM 能够处理连接的文本和图像输入令牌。
相比之下,跨模态注意力架构(方法 B)在注意力层中直接整合图像和文本嵌入,采用了跨注意力机制。
如果您对更多细节感兴趣,我在今年早些时候专门撰写了一篇关于多模态 LLM 的文章,逐步介绍了这两种方法:理解多模态 LLM -- 主要技术和最新模型的介绍。
9.2 Nvidia 的混合方法
鉴于今年的多模态发展,在我看来,NVIDIA 的论文 NVLM: 开放前沿级多模态 LLM 因其对这些多模态方法的全面比较而脱颖而出。他们并没有专注于单一方法,而是直接比较了:
-
方法 A:统一嵌入解码器架构(“仅解码器架构”,NVLM-D),
-
方法 B:跨模态注意力架构(“基于交叉注意力的架构”,NVLM-X),
-
混合方法(NVLM-H)。
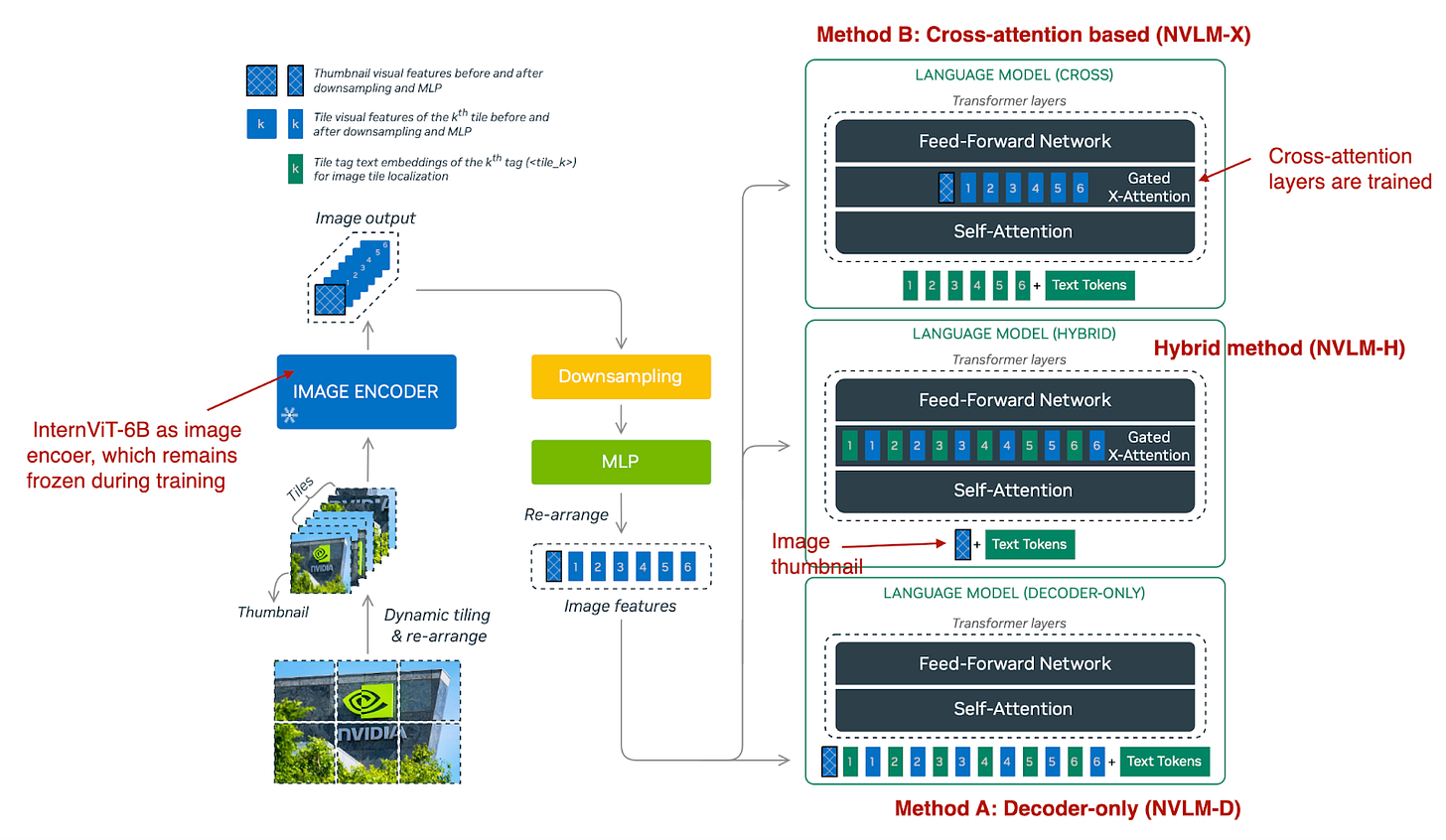
三种多模态方法的概述。(来自NVLM: 开放前沿类多模态LLM论文的注释图: https://arxiv.org/abs/2409.11402)
如上图所示,NVLM-D 与方法 A 对应,NVLM-X 则对应方法 B,如前所述。混合模型(NVLM-H)结合了两种方法的优点:它首先接受图像缩略图作为输入,然后通过交叉注意力处理动态数量的补丁,以捕捉更精细的高分辨率细节。
总结关键发现如下:
-
NVLM-X:为高分辨率图像提供卓越的计算效率。
-
NVLM-D:在与OCR相关的任务中提供更高的准确性。
-
NVLM-H:结合两种方法的优点,以实现最佳性能。
9.3 2025年的多模态LLMs
多模态大型语言模型(LLMs)是一个有趣的主题。我认为它们是常规文本基础LLMs的下一个逻辑发展。大多数LLM服务提供商(如OpenAI、Google和Anthropic)支持多模态输入,例如图像。就我个人而言,我大约1%的时间需要多模态能力(通常是像“提取以Markdown格式呈现的表格”这样的需求)。我确实期望开放权重的LLMs默认是纯文本基础的,因为这会减少复杂性。同时,我也认为随着工具和API的发展,我们将看到更多的选择和开放权重LLMs的广泛使用。
10. 十月:复制OpenAI o1的推理能力
我选择的十月文章是 O1复制之旅:战略进展报告 -- 第一部分。(2024年10月)由Quin及其同事撰写。
OpenAI的ChatGPT的o1(现在是o3)获得了显著的关注,因为它们似乎代表了在推理任务上提升LLMs性能的范式转变。
OpenAI的o1的具体细节仍未披露,几篇论文试图描述或复制它。那么,我为什么选择这篇呢?它独特的结构和关于学术研究现状的更广泛哲学论点引起了我的共鸣。换句话说,它有一些独特之处,使其成为一个有趣的选择。
10.1 快捷学习与旅程学习
本文的一个关键点是研究人员的假设,即O1采用了一种称为旅程学习的过程,而不是快捷学习,如下图所示。
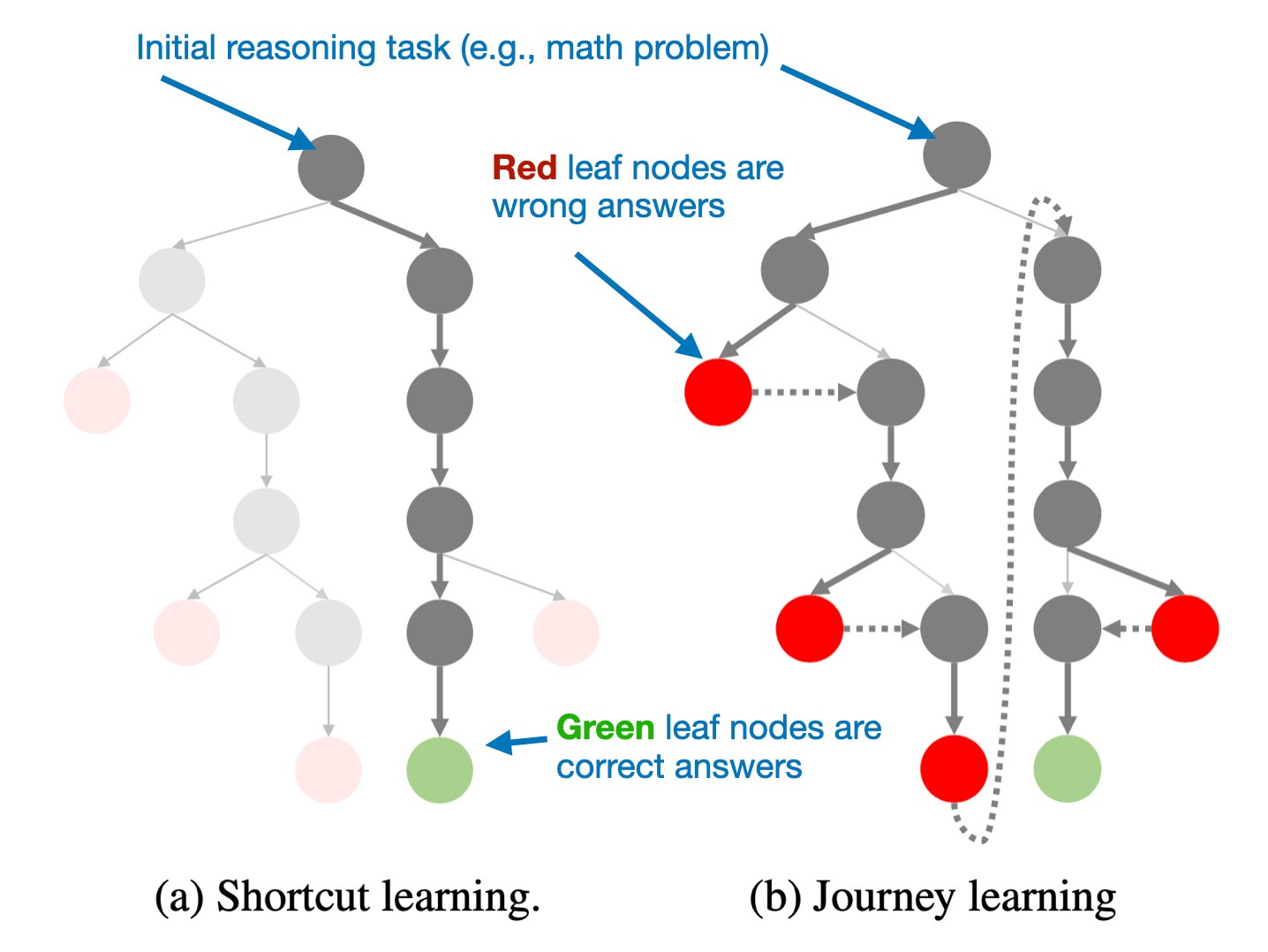
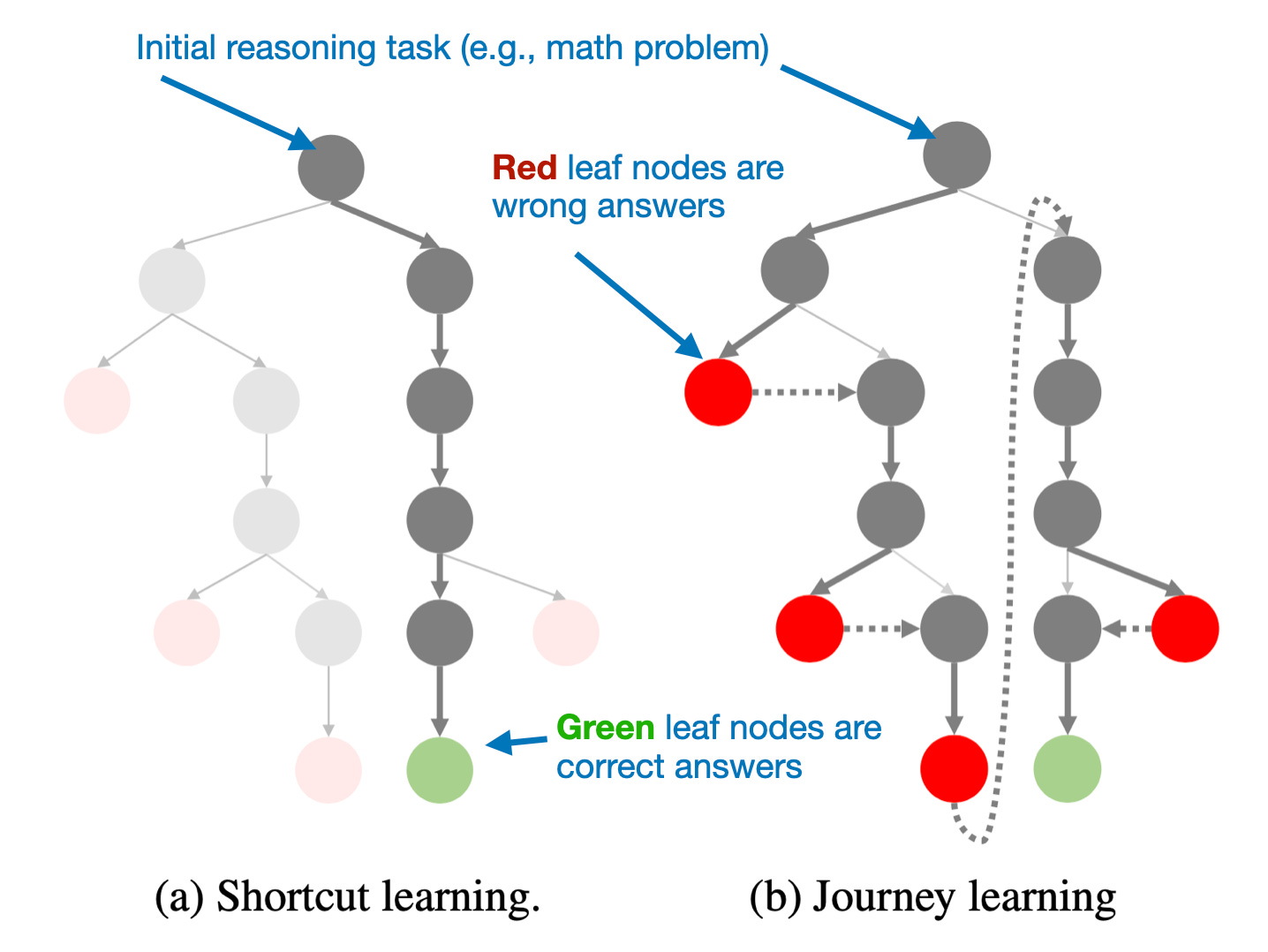
传统上,LLM是在正确解决路径上进行训练的(快捷学习);而在旅程学习中,监督微调涵盖了整个试错纠正过程。来自O1复制报告的注释图,https://arxiv.org/abs/2410.18982
值得注意的是,旅程学习方法在某种程度上与之前在本文“8. 八月:通过扩展推理时间计算来改善LLM”部分讨论的基于树或束搜索的方法相似。
然而,细微的区别在于,研究人员为模型微调创建了旅程学习训练示例,而不仅仅是在推理过程中应用这种技术。(值得一提的是,我找不到他们用于增强推理过程的技术的任何信息。)
10.2 构建长思维
研究人员构建了一个推理树,以从中推导出扩展的思维过程,强调试错。这种方法与传统方法有所不同,后者优先考虑找到通往正确答案的直接路径,并具有有效的中间步骤。在他们的框架中,推理树中的每个节点都附有由奖励模型提供的评分,指示该步骤是正确还是错误,并附有理由来证明这一评估。
接下来,他们通过监督微调和DPO训练了一个深度搜索数学模型(deepseek-math-7b-base)。在这里,他们训练了两个模型。
- 首先,他们使用了传统的快捷训练范式,仅提供正确的中间步骤。
- 其次,他们使用他们提出的旅程学习方法对模型进行了训练,该方法包括了思维过程三以及正确和错误的答案、回溯等。
(附注:他们在每种情况下仅使用了327个示例!)
如下面的图所示,旅程学习过程在MATH500基准数据集上明显优于快捷学习。
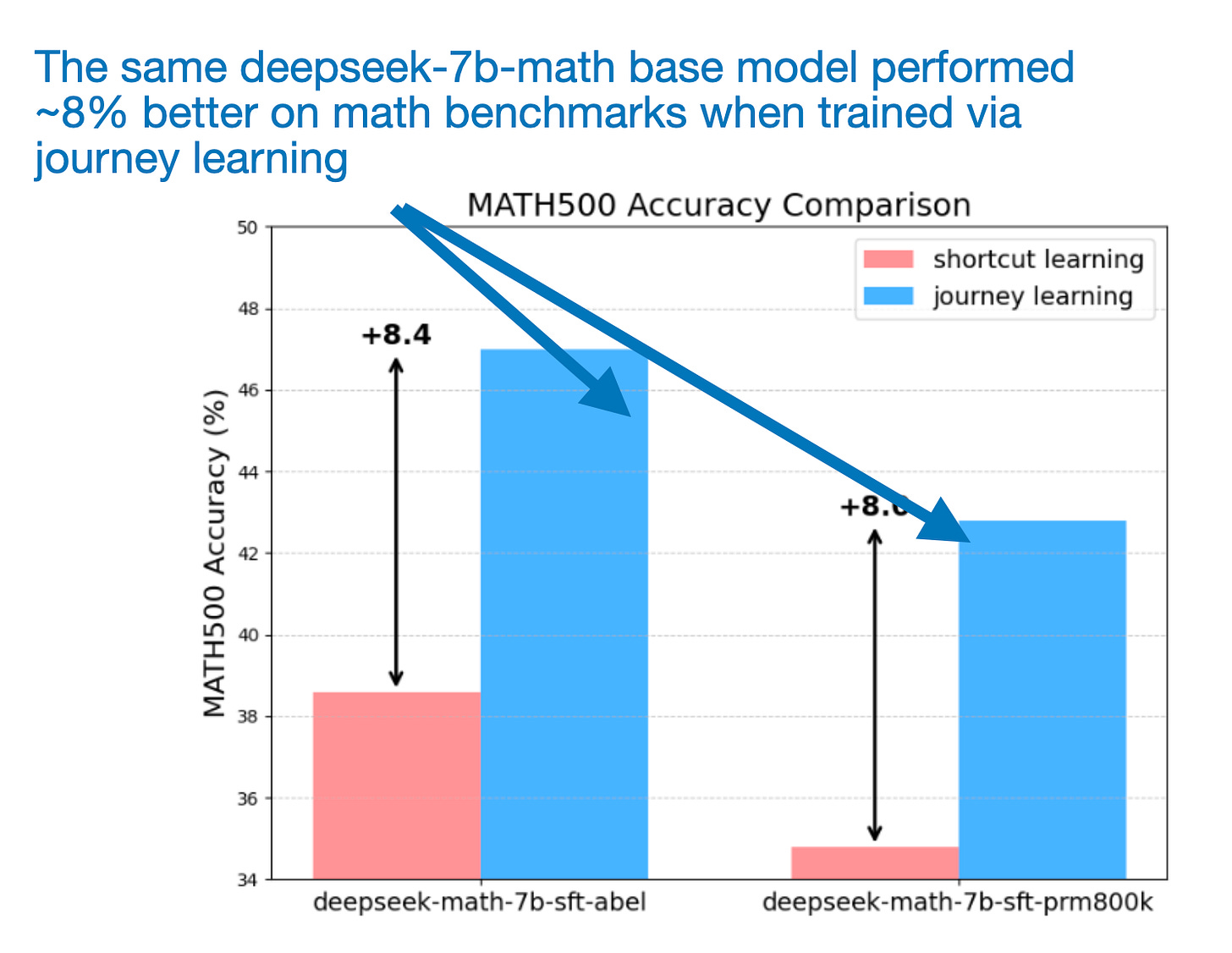
使用快捷学习和旅程学习训练的LLMs。来自O1复制报告的注释图,https://arxiv.org/abs/2410.18982
10.3 蒸馏 -- 快速解决方案?
一个月后,团队发布了另一份报告:O1复制旅程 -- 第二部分:通过简单蒸馏超越O1预览,重大进展还是惨痛教训?(2024年11月)由黄及其同事撰写。
在这里,他们使用了一种蒸馏方法,意味着他们通过仔细的提示从o1中提取思维过程,以训练模型达到相同的性能。由于这是一篇较长的文章,我不会详细讨论,但我想分享该论文中的一个有趣图表,总结了收集长思维数据的成本权衡。
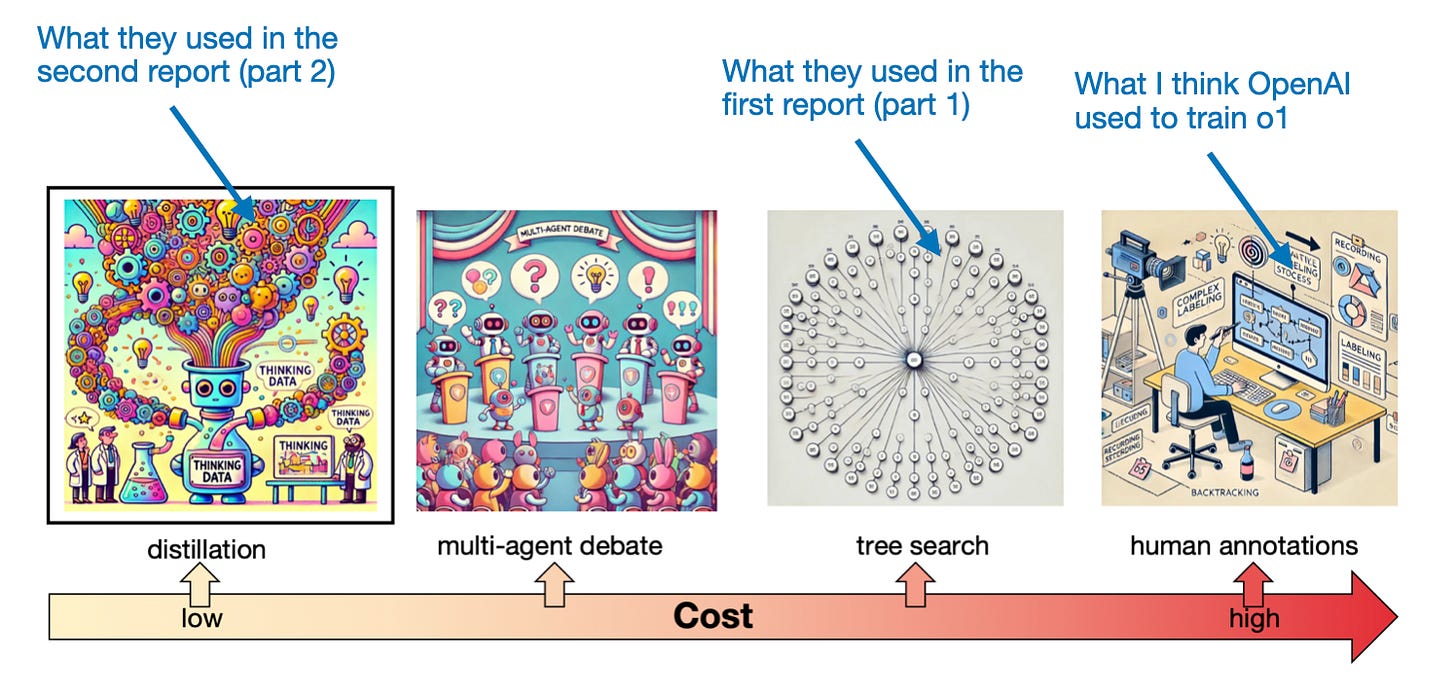 他们在这种蒸馏方法上取得了非常好的性能,表现与o1-preview和o1-mini相当。然而,随着这些实验的进行,研究人员也分享了一些有趣且重要的观点,关于这种方法下的研究现状,我将在下一节中总结。
他们在这种蒸馏方法上取得了非常好的性能,表现与o1-preview和o1-mini相当。然而,随着这些实验的进行,研究人员也分享了一些有趣且重要的观点,关于这种方法下的研究现状,我将在下一节中总结。
10.4 人工智能研究的现状
第二部分报告的一个重点是“简单蒸馏的苦涩教训”。当然,蒸馏在实践中效果很好,但这并不是推动进步的动力。在最佳情况下,使用蒸馏时,你只是匹配了现有上游模型的性能(但并没有创造新的性能记录)。以下是论文中的三段引述,可能对当前的现状发出警示:
-
“从‘它是如何工作的’到‘什么有效’的转变,代表了研究心态的根本变化,这可能对该领域未来的创新能力产生深远的影响。”
-
“这种对第一性原理思维的侵蚀尤其令人担忧,因为它削弱了科学创新的基础。”
-
“产生快速结果的压力可能会掩盖更深入技术研究的价值,而学生们可能会被劝阻去追求更具挑战性、基础性的研究方向。”
我个人的看法是,我仍然认为学术实验室(如今也常与行业合作)中涌现出大量伟大且重要的想法,它们可以非常实用且具有影响力。(我想到的几个我最喜欢的例子是LoRA和DPO。)问题在于,许多有前景的想法从未在大规模上进行测试,因为大学通常没有进行此类测试所需的大量资源。 我不确定完美的解决方案是什么,我也意识到公司不能随便泄露其商业机密。但如果公司在使用学术论文中的想法时能够公开承认,那将非常有帮助。这种认可对于激励和奖励那些将其研究成果免费提供的研究人员来说意义重大。此外,这也有助于推动该领域的发展,了解哪些方法在实践中真正有效。
10.5 在o1(和o3)背景下的LLM未来
《O1复制之旅》论文是否复制了o1背后的确切机制?可能没有。但这仍然是一本充满有助于取得更好结果的想法的有价值的读物。我相信像o1和o3这样的“长期思考”模型将在LLM研究中继续发挥关键作用。它们的运行成本较高,但基本上是推理任务性能的金标准或上限。
但由于其较高的成本,o1类型的模型并不总是每种情况的最佳选择。对于语法修正或翻译等简单任务,我们可能不需要一个重推理的模型。这一切归结为成本和效用之间的平衡。我们根据预算、延迟和其他因素选择适合工作的LLM。
11. 十一月:LLM精度的扩展法则
我最初考虑选择Allen AI的Tulu 3: Pushing Frontiers in Open Language Model Post-Training论文,因为他们详细描述了Llama后训练方法和配方,包括DPO与PPO的消融研究,以及一种新的偏好对齐方法,称为可验证反馈的强化学习,其中使用可验证查询,可以轻松生成真实答案(例如数学和代码问题),而不是奖励模型。
但经过一些内部讨论,我最终决定选择Kumar及其同事的Scaling Laws for Precision论文(2024年11月),因为它为Chinchilla缩放法则提供了急需的更新,该法则源自2022年的Training Compute-Optimal Large Language Models论文,用于确定计算最优的LLM参数数量和预训练数据集大小。
简而言之,Precision Scaling Laws论文(2024年11月)扩展了Chinchilla的缩放法则,以考虑低精度设置(16位及以下)下的训练和推理,这在近年来变得非常流行。例如,这篇论文将各种低精度和量化相关的观察统一为一个单一的功能形式,预测低精度训练和后训练量化带来的额外损失。
11.1 Chinchilla缩放法则回顾
2022年Training Compute-Optimal Large Language Models论文中的原始Chinchilla缩放法则模型展示了LLM参数数量(N)和数据集大小(D)如何共同影响LLM的验证损失,并作为决定LLM和训练数据集大小的指导原则。 作为经验法则,在固定计算预算下,数据集大小 D 与参数数量 N 之间的最佳权衡大约是 D/N ≈ 20。
这种数据-参数比率通常被称为“Chinchilla-optimal”,因为它在相同的总训练成本下,能够产生比其他比率更低的验证损失。
不过,需要注意的是,现代有许多例外;例如,Llama 3 团队训练了 15 万亿个标记,如前所述,对于 80 亿版本来说,这将是 15,000,000,000,000 ÷ 8,000,000,000 = 1,875。
在我看来,比起确切的数据-参数比率,更重要的是要认识到模型和数据集的规模必须成比例地进行调整。
11.2 低精度训练
在进一步讨论(或更确切地说,总结)低精度缩放法则之前,让我先简要介绍一下用于 LLM(或深度神经网络)权重的不同数值精度格式。
据我所知,以下是用于训练 GPT 2 和 3 以及 Llama 2 和 3 模型的精度格式,以供比较:
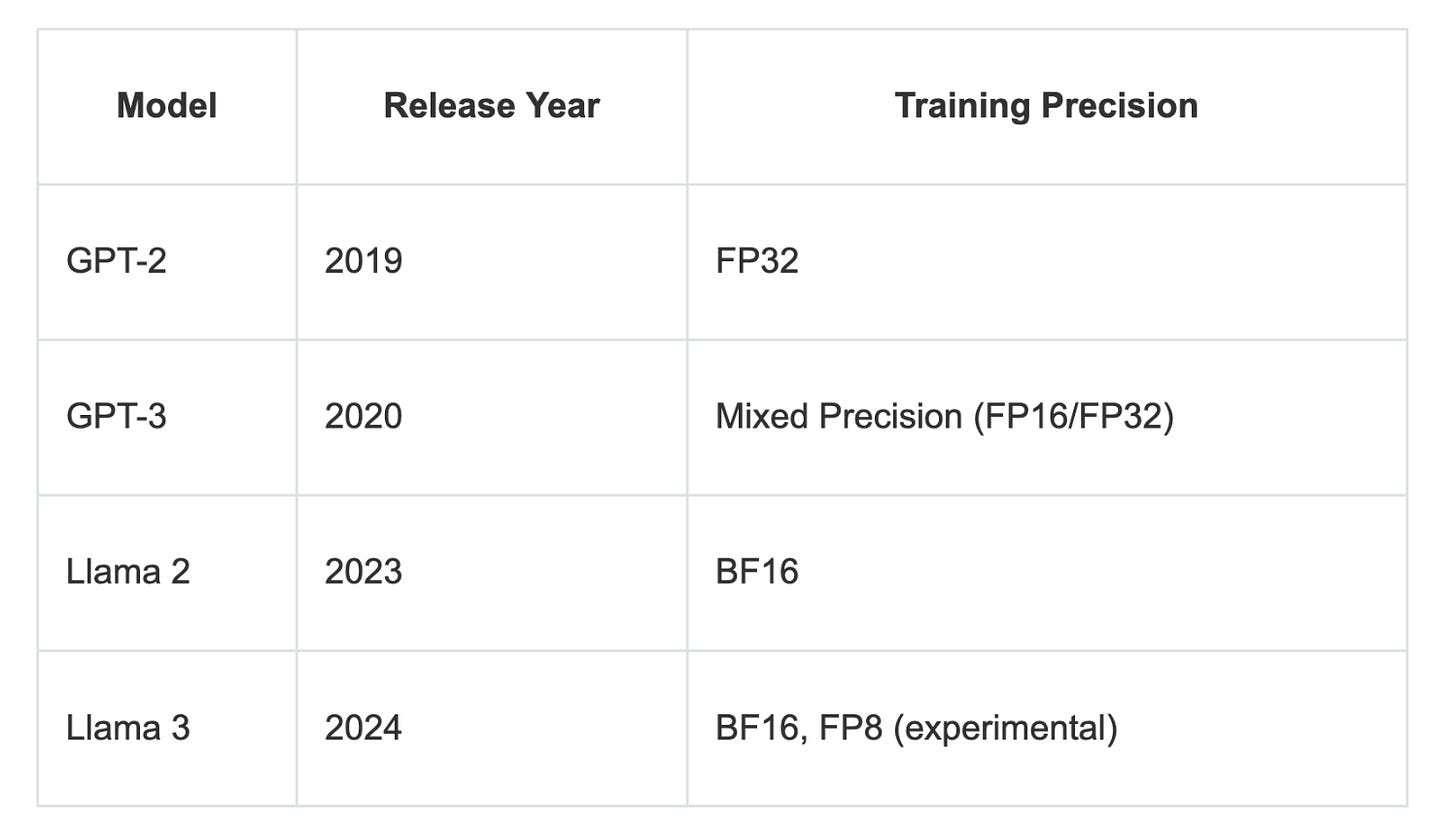
Float32 是一种标准的 32 位浮点格式,广泛用于训练深度神经网络,因为它在范围和精度之间提供了良好的平衡。如今,所有低于 float32 的格式都被视为低精度(尽管“低”的定义有点像“大型语言模型”中的“大型”,是一个不断变化的目标)。
Float16,或半精度,仅使用 16 位,节省内存并加快计算速度,但提供的动态范围较窄。
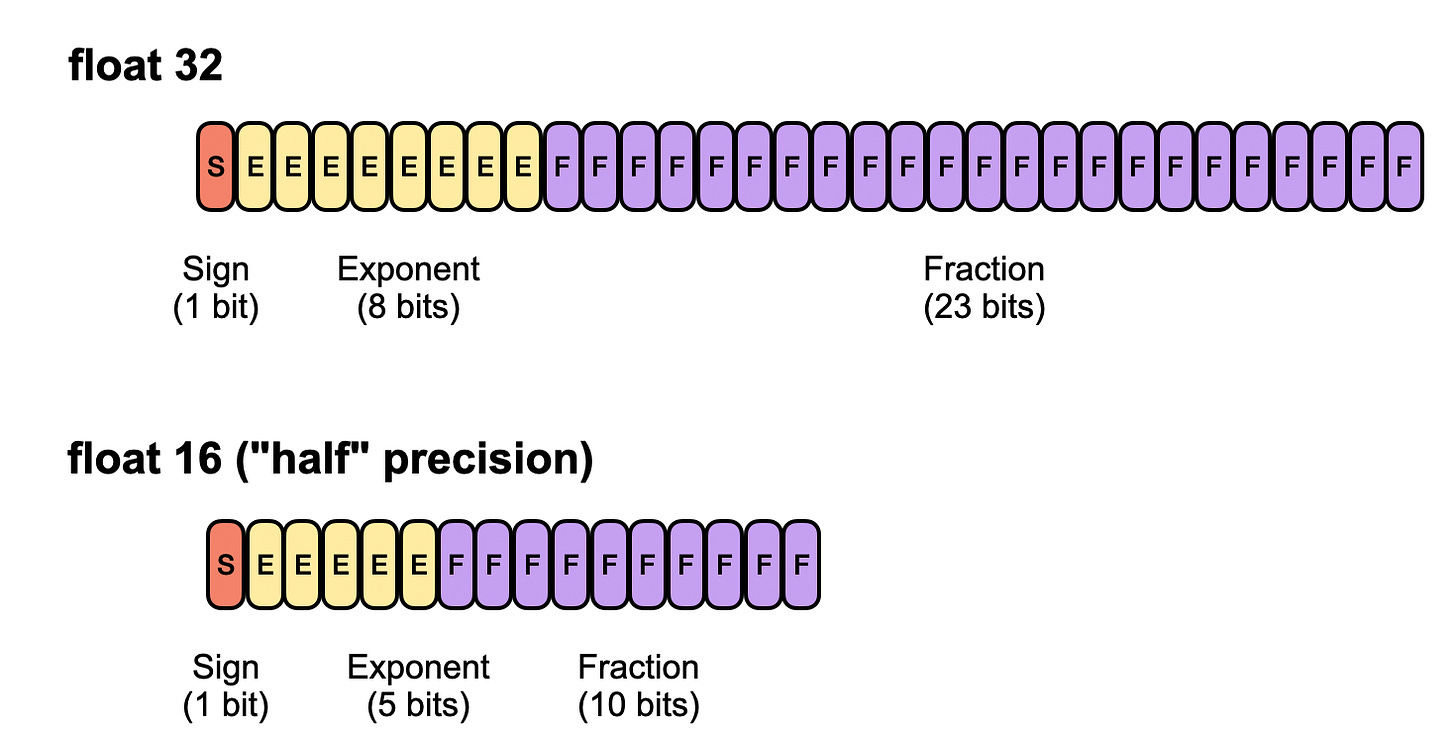
32位与16位浮点精度的比较
Bfloat16(脑浮点16)也是一种16位格式,但在浮点16的精度上做了一些妥协,以获得更大的指数,从而更有效地表示非常大和非常小的数字。因此,bfloat16可以帮助避免深度学习应用中的数值溢出或下溢,尽管其较低的精度仍可能导致舍入错误。
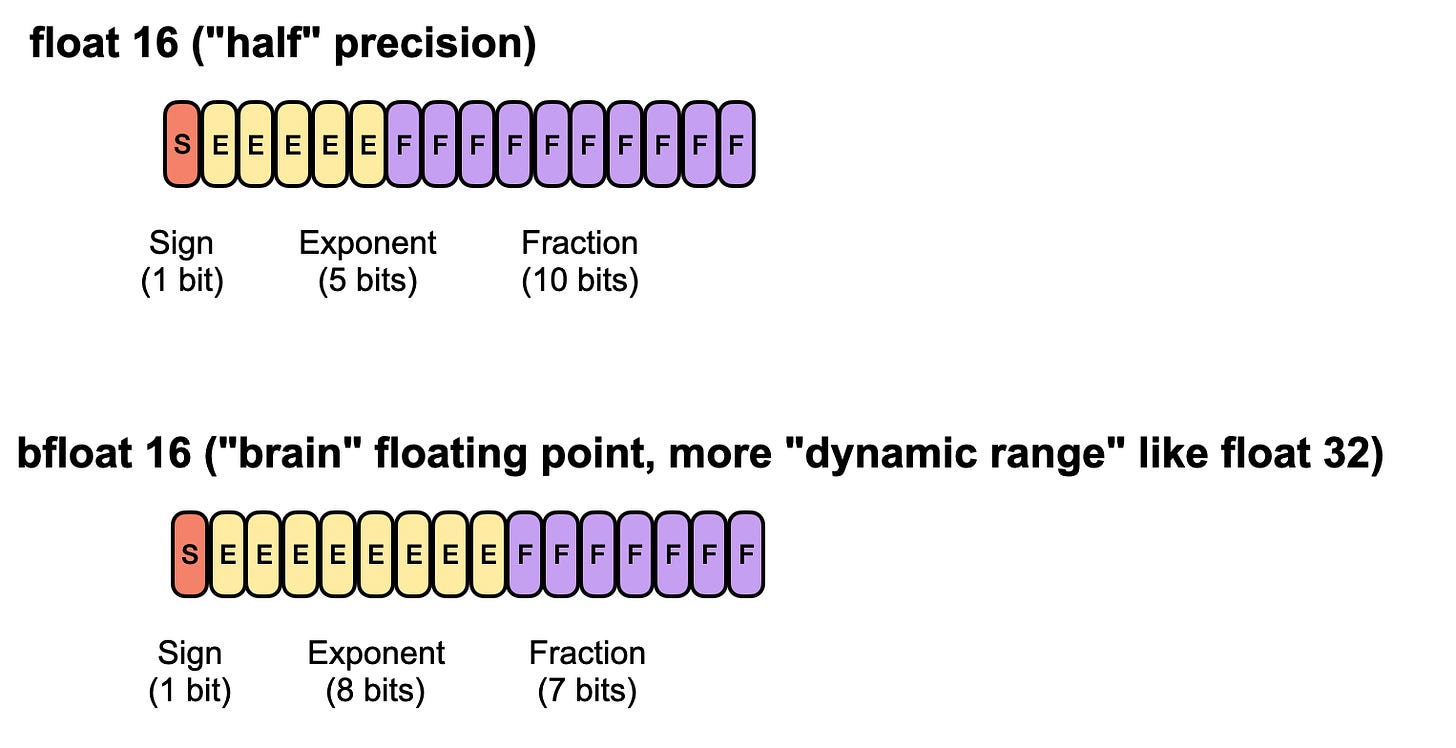
常规16位浮点与流行的16位脑浮点精度的比较
如果您想了解更多关于不同精度格式及其对LLM模型行为的影响,您可能会喜欢我之前的文章 缺失的位:Llama 2 权重已更改 中的详细介绍。
还要注意,我仅展示了32位和16位格式,而目前在训练中还存在向更低精度(例如,在Llama 3论文中提到的8位格式)发展的竞争。(在12月26日发布的 DeepSeek-v3模型 完全是在8位浮点精度下进行预训练的。)
11.3 精度缩放法则要点
这是一篇内容丰富且有趣的论文,我推荐大家完整阅读。然而,为了直接切入主题,研究人员通过添加一个“精度”因子 P 来扩展原有的 Chinchilla 规模法则。具体来说,他们将模型参数数量 N 重新解释为“有效参数数量”,该数量会随着精度的降低而缩小。(有关数学公式,请参阅论文。)
此外,他们还添加了一个额外的项,以捕捉后训练量化如何降低模型性能。(我意识到我没有写关于量化的介绍,但由于这篇文章已经过长,我可能需要将其推迟到另一个时间。)
下面的图表很好地说明了更多的预训练数据并不总是更好,如果模型在训练后以非常小的精度(int3)进行量化,实际上可能会造成伤害,这让我觉得非常有趣。
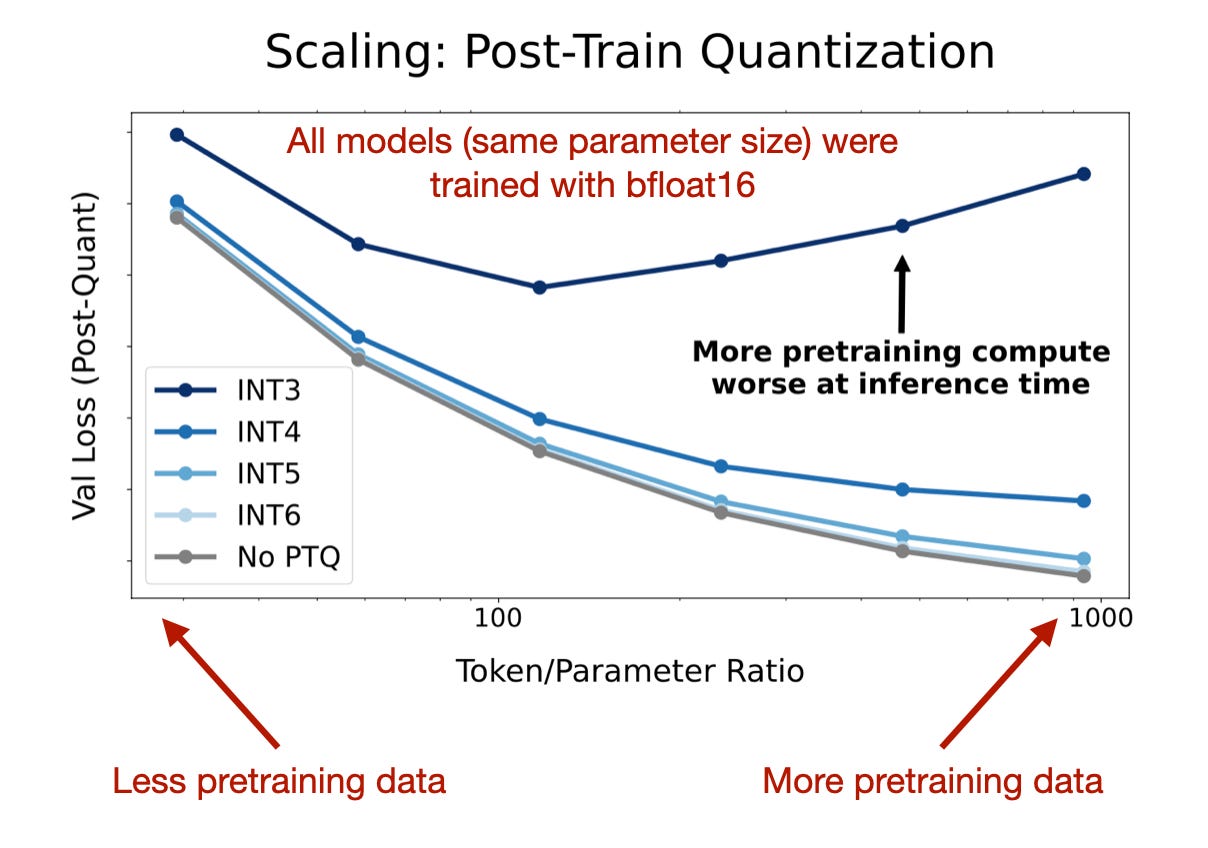
更多训练数据对各种后量化格式的验证损失的影响
因此,从上面的图中可以得出一个结论:在更多数据(如 Llama 3)上训练的模型在训练后变得更难以量化为低精度格式,因为它们在过多数据上“过度训练”。
11.4 2025年的模型规模法则
除了对 Chinchilla 规模法则提供急需的更新外,关于精度规模法则的研究还为2025年面临的一个关键挑战提供了有趣的视角:随着像 LLaMA-3 这样的模型在更大数据集上进行训练,它们可能会变得更难以量化为低精度格式(如 INT3),而不会损失性能。 这一发现强调了重新思考“数据越多越好”心态的必要性,需要在数据集规模与高效推理的实际限制之间取得平衡。这也是推动硬件优化的重要见解。
我认为在这些规模法则研究中,往往被忽视的一个方面是数据集的质量。我认为预训练数据的性质可能会产生显著影响。(关于这一点将在下面的Phi-4讨论中详细说明。)
12. 十二月:Phi-4与从合成数据中学习
在2024年下半年发布了几款有趣的模型,包括在圣诞节发布的令人印象深刻的 DeepSeek-V3。虽然这可能不是最大的模型发布,但最终我决定选择微软的 Phi-4技术报告,因为它提供了关于合成数据使用的有趣见解。
12.1 Phi-4性能
Abdin及其同事在2024年12月发布的 Phi-4技术报告 描述了微软最新的140亿参数开放权重大型语言模型(LLM)的训练。Phi-4特别有趣之处在于,它主要是在由GPT-4o生成的合成数据上进行训练的。根据基准测试,它的表现优于其他相似规模的LLM,包括其前身Phi-3,后者主要是在非合成数据上进行训练的。
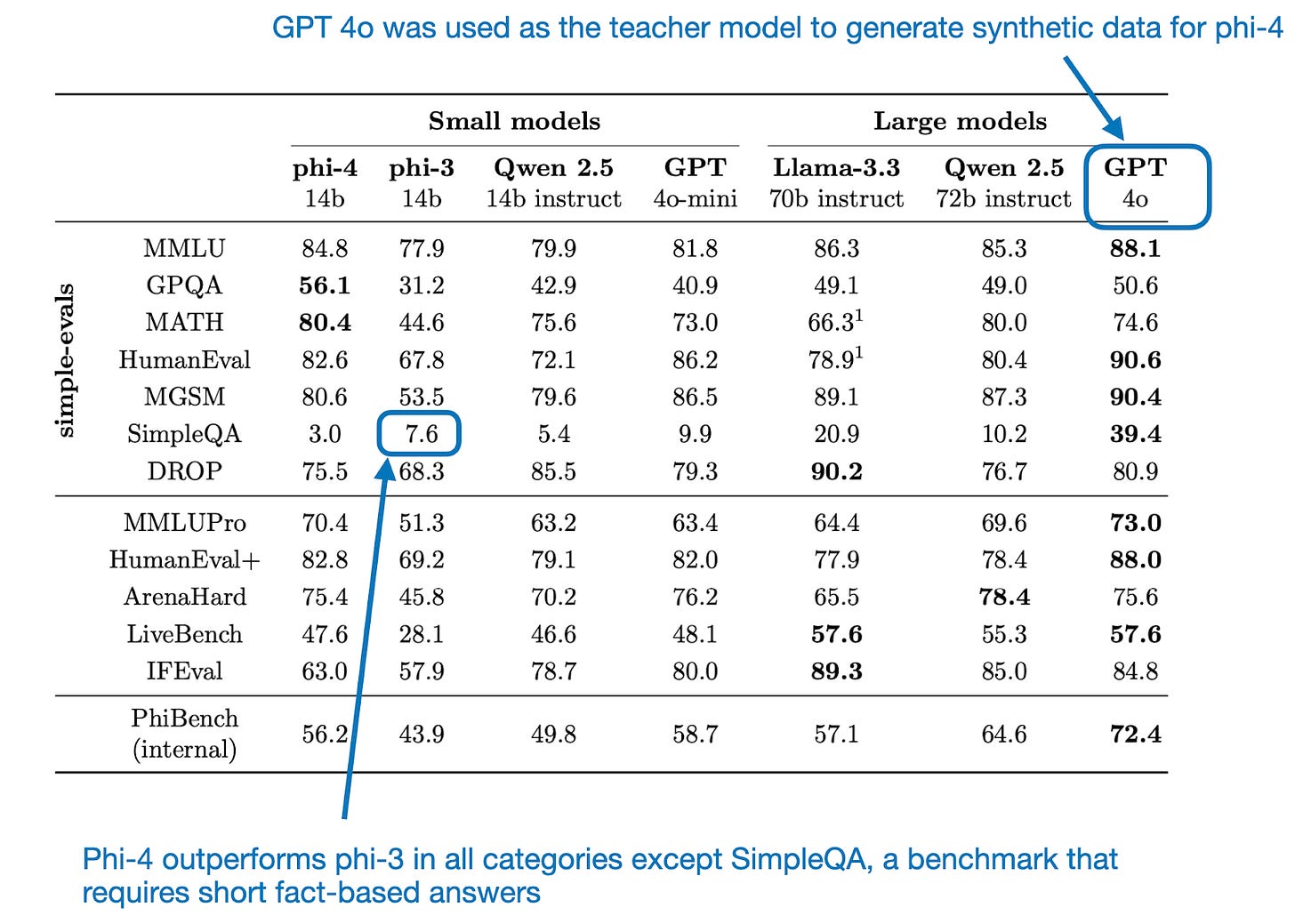
Phi-4与其他相似及不同规模模型的性能比较(来自Phi-4论文的注释表格,https://arxiv.org/abs/2412.08905) 我不太确定为什么模型在SimpleQA上的表现较差,如上表所示。但一个可能的解释是,SimpleQA是一个相对较新的基准,于2024年10月30日发布。由于它是OpenAI作为其评估套件的一部分开发的,因此可能没有包含在GPT-4o的训练数据中,也没有纳入网络爬取的数据集中。此外,由于GPT-4o被用来生成用于此评估的合成数据,因此在训练过程中没有任何模型接触过SimpleQA。然而,phi-4可能在其他基准上过拟合,这可能解释了它在这个未见过的SimpleQA数据集上的相对较低表现。无论如何,这只是我的假设。
12.2 合成数据学习
在总结本文中呈现的一些消融研究之前,让我们先看看数据集的组成。
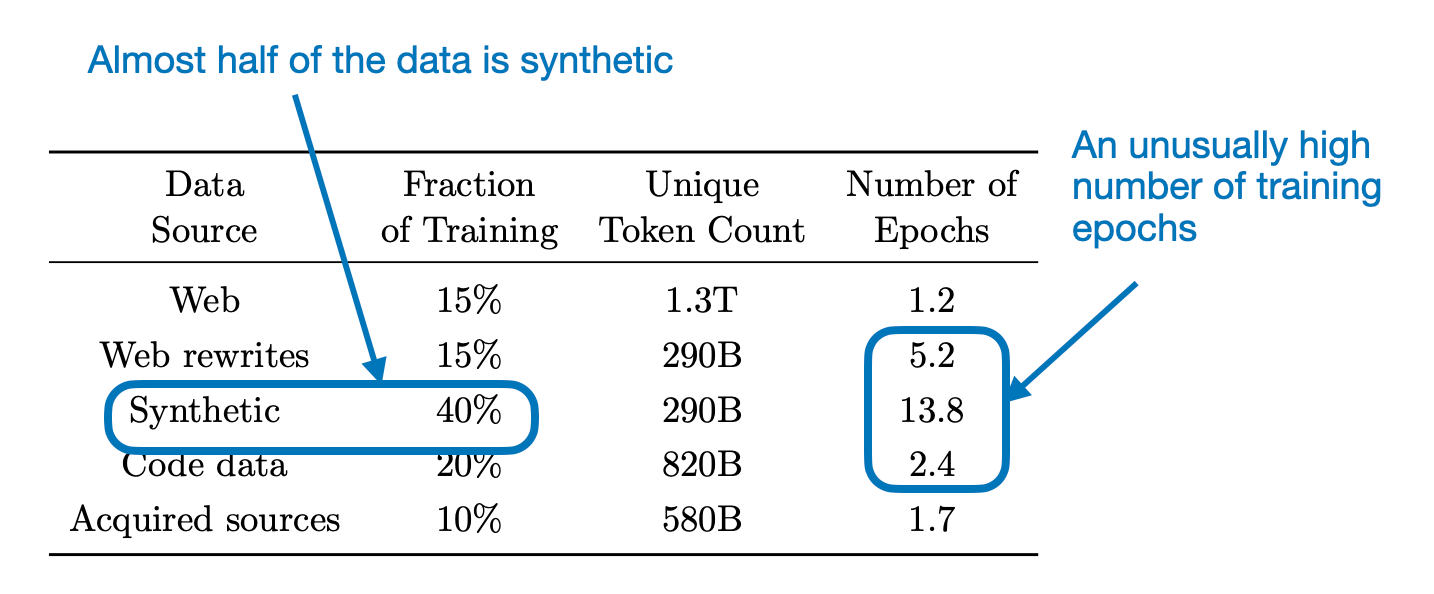
用于训练phi-4的数据集混合(来自phi-4论文的注释表,https://arxiv.org/abs/2412.08905)。
研究人员观察到,尽管合成数据通常是有益的,但仅在合成数据上训练的模型在基于知识的基准上表现不佳。在我看来,这引发了一个问题:合成数据是否缺乏足够的知识特定信息,还是包含了更高比例的事实错误,例如由幻觉引起的错误?
与此同时,研究人员发现,在合成数据上增加训练轮次比仅仅增加更多的网络数据更能提升性能,如下图所示。
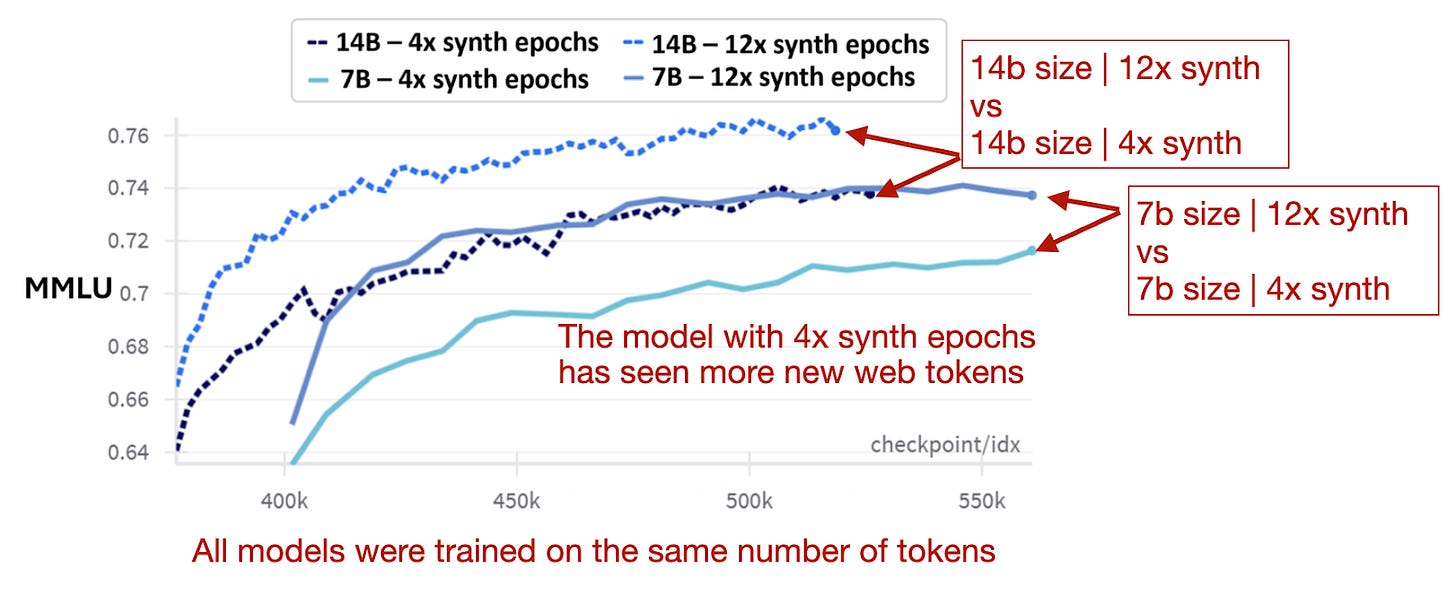
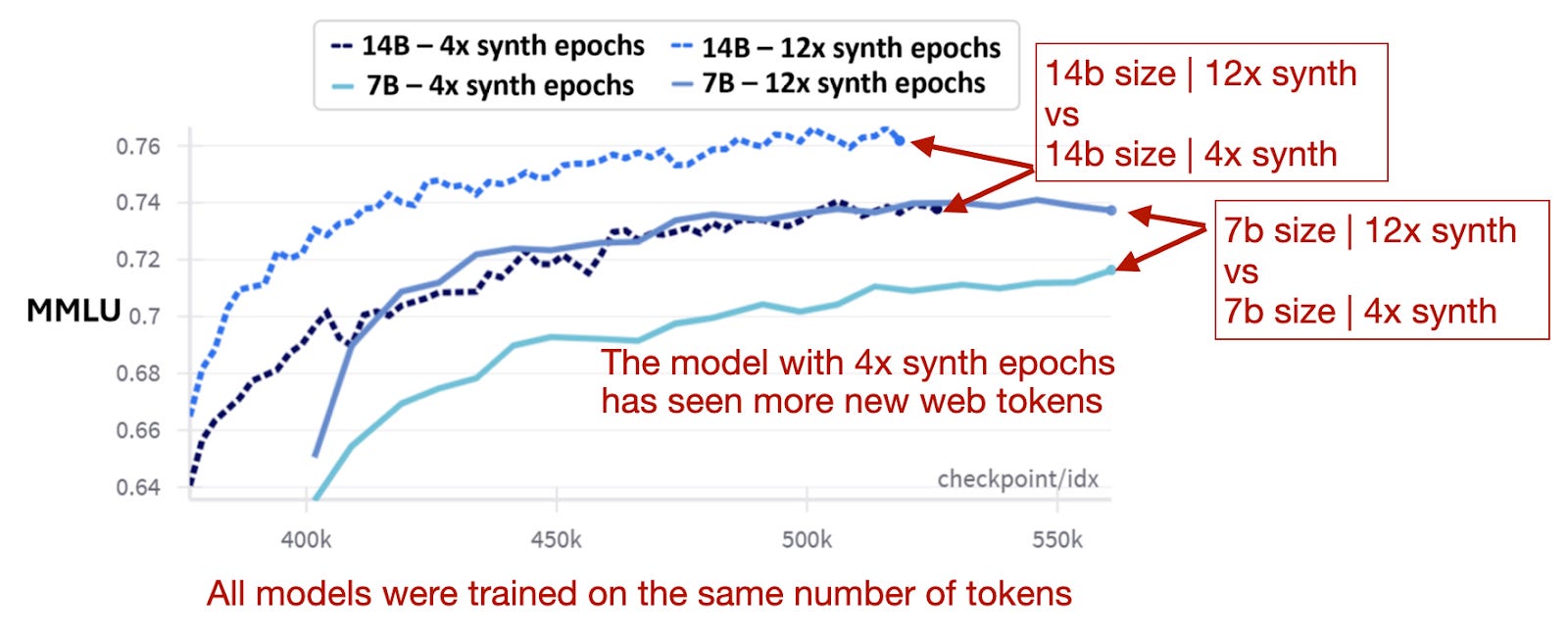
模型性能比较,不同合成/网络数据集比例。 (来自phi-4论文的注释图,https://arxiv.org/abs/2412.08905)。
总之,合成数据在混合中占比过高会对基于知识的性能产生负面影响。然而,在更平衡的合成数据与网络数据混合中,增加对合成数据集的迭代次数(训练轮数)是有益的。
12.3 合成数据的未来重要性
phi-4技术报告提供了关于合成数据使用的有趣见解,特别是它在模型预训练中的高度有效性。尤其是因为关于模型和数据集规模的扩展法则似乎已经趋于平稳(尽管Llama 3论文指出他们尚未在15T标记水平上看到收敛),研究人员和工程师正在寻找替代方法来不断推动边界。
当然,预训练和特别是后训练技术的改进和增加可能仍将是推动重大变革的关键因素之一。不过,我认为合成数据的使用将被视为一种有效的方法,来创造 a) 使用更少数据的预训练基础模型,或 b) 创建更优秀的基础模型(考虑到Llama 3数据集的15万亿标记加上40%的合成数据标记)。 我将高质量数据的使用视为类似于迁移学习。与其在原始、非结构化的互联网数据上预训练模型并在后期进行精细调整,不如利用由高质量模型(例如已经经过广泛精细化的GPT-4o)生成的(部分)合成数据,这可能会起到一种助推作用。换句话说,使用高质量的训练数据可能使模型从一开始就能更有效地学习。
结论与展望
希望你觉得这些研究总结有用!和往常一样,这篇文章的长度超出了我最初的预期。但让我以一个相对简短而精炼的部分结束,谈谈我对2025年的预测(或期望)。
多模态大型语言模型
去年,我预测大型语言模型将变得越来越多模态。现在,所有主要的专有大型语言模型提供商都提供多模态(或至少是图像)支持。因此,这一转变现在已经全面展开,我们也将看到更多的开源努力朝这个方向发展。
根据我所见和阅读的内容,多模态论文的数量确实有了显著增加。也许会跟随我开放源代码的微调方法和资源;尽管我认为对于许多使用案例,仅文本就足够,并将继续足够,主要的关注点将是开发更好的推理模型(如o1和即将推出的o3)。
计算效率
预训练和使用大型语言模型的成本相对较高。因此,我预计在可预见的未来,我们将看到更多聪明的技巧来提高大型语言模型的计算效率。作为参考,训练最近的 DeepSeek-v3模型 的成本将达到500万美元,假设GPU租赁的标价(这还不包括超参数调优、失败的运行和人员成本)。

来自DeepSeek-v3报告的粗略计算,链接:DeepSeek_V3.pdf
顺便提一下,根据Meta AI官方的Llama 3模型卡,Llama 3 405B的计算需求甚至高达约10倍(3084万GPU小时对比266万GPU小时)。
使大型语言模型(LLMs)高效的常见技术示例(尽管并非所有技术在训练期间都适用)包括专家混合(如我第一部分文章中讨论的)、Llama模型中的分组查询注意力等,还有许多其他技术。另一个有趣的例子是使用多头潜在注意力,这在DeepSeek模型中被发现,可以使多头注意力中的KV缓存更加高效。
最近另一个有趣的方向是针对模型输入。例如,最近提出的字节潜在变换器通过动态将字节编码为基于熵的补丁来提高效率,从而优化计算以实现可扩展性和更快的推理,而无需进行标记化。
状态空间模型
你可能注意到我今年没有涵盖状态空间模型。这是因为我目前的重点主要集中在基于变换器的LLMs上。虽然我觉得状态空间模型非常有趣,但在这个阶段它们似乎仍然相当实验性。此外,变换器在广泛的任务中继续展现出卓越的性能,使得考虑替代方案的吸引力不大。 然而,这并不意味着在状态空间模型方面没有任何进展。我看到了一些有趣的论文。在这个领域,我注意到一个有趣的趋势是,它们现在或多或少都是混合模型,整合了来自变换器模型的自注意力机制。例如,
从这个意义上说,它们的计算成本也在增加。通过对基于变换器的LLM进行效率调整,并向状态空间模型添加注意力机制,如果当前趋势持续下去,它们可能会在某个中间点相遇。不过,这绝对是一个值得关注的有趣研究领域。
通过扩展实现LLM进展
在年末,也有一些关于LLM扩展“结束”的讨论,理由是没有更多的互联网数据。这一讨论源于Ilya Sutskever(OpenAI的联合创始人之一,也是GPT论文的共同作者)在NeurIPS会议上的演讲,但不幸的是,我今年无法参加会议,因此对细节不太熟悉。
无论如何,这是一个有趣的观点,因为互联网的增长速度是指数级的。我可以 找到资源说它每天增长 “15.87太字节的数据。”当然,挑战在于并非所有数据都是文本或对LLM训练有用。然而,正如我们在Phi-4中看到的,数据策划和精炼仍然有很多机会,可以帮助从训练数据中实现一些飞跃。 我同意通过数据扩展所带来的收益递减现象。不过,我预计随着我们可能正朝着平台期发展,收益会变得更小。不过,这并不是坏事,因为它带来了其他改进的机会。
我期待未来收益的一个显著领域是后训练。我们已经在最近的LLM发布中看到了这一领域的一些发展,正如我去年夏天在我的新LLM预训练和后训练范式文章中所写的那样。
我对2025年的期待
今年我非常享受对各种Llama模型(3、3.1和3.2)的调试和(重新)实现。我非常期待Llama 4的发布,希望它也能以小巧便捷的尺寸推出,这样我就可以在我的笔记本电脑或经济实惠的云GPU上进行实验。
此外,这也是我希望更多地尝试特定用途模型微调的一年,而不是生成通用聊天机器人(这个领域已经相当拥挤)。我们在各种代码和数学模型中看到了一些这样的尝试(最近的Qwen 2.5 Coder和Qwen 2.5 Math让我想起了这一点,但遗憾的是我还没有机会在本报告中涵盖它们)。
无论如何,我可以继续列出这个愿望清单和计划,因为2025年将是另一个有趣且快速发展的年份!这肯定不会无聊,这是可以肯定的!
本杂志是一个个人热情项目。对于那些希望支持我的人,请考虑购买我的从零开始构建大型语言模型一书。(我相信您会从这本书中获得很多,因为它以其他地方找不到的细节水平解释了LLM的工作原理。) 如果您读过这本书并有几分钟的时间,我将非常感激您能写一篇简短的评论。这对我们作者帮助很大!
您的支持意义重大!谢谢!