MinerU:一键提取PDF中的表格/图表/公式,知识库搭建必备
2025年2月21日
遇到这些情景,开启打工人奔溃的一天:
领导下班前丢来100页PDF报表让整理😭
论文里的数学公式根本没法复制粘贴😭
扫描件表格手动录入Excel到凌晨3点😭
在搭建本地知识库,或者准备训练专业领域的大模型数据时,时常会愁怎么处理一大堆专业文献。
关键是,这些文档不只是文字!还有大量数学公式、复杂表格、图表说明,甚至跨页的多栏布局。
怎么办?
成千上万个文件,要是手工处理,怕是要猝死在工位上了。
现在安利大家一个神器——MinerU!

1
MinerU是上海人工智能实验室开发的开源产品,专门为解决海量专业文献转换的难题而生。
它不是简单地提取文本,更重要的是能完整保留文档的语义结构,把PDF转成机器可读的Markdown或JSON格式,完美满足了构建知识库和训练模型的需求。
这对搭建知识库,准备训练模型所需数据,非常有帮助!
2
说到它的功能,真是让人眼前一亮。
面对复杂的学术论文,MinerU能智能识别所有内容,把数学公式自动转成LaTeX,复杂表格变成HTML,连图片说明都不会丢。
更绝的是它还会自动清理页眉页脚这些干扰项,确保导出的内容逻辑性完整。
就算遇到扫描版的老论文也不怕,内置的OCR系统支持84种语言,日语俄语都不在话下。
最近的更新还带来了超强的批量处理能力。
不管是本地的论文库还是在线文档,PDF、Word、PPT通通能处理。
技术上它用了一套完整的处理流程。先用布局分析找出文档结构,然后用专门的模型处理公式和表格,最后通过智能排序生成结构化数据。
3
要用起来也特别简单。
想快速体验就去mineru.net玩在线demo,适合偶尔使用。
方式一**:下载客户端**
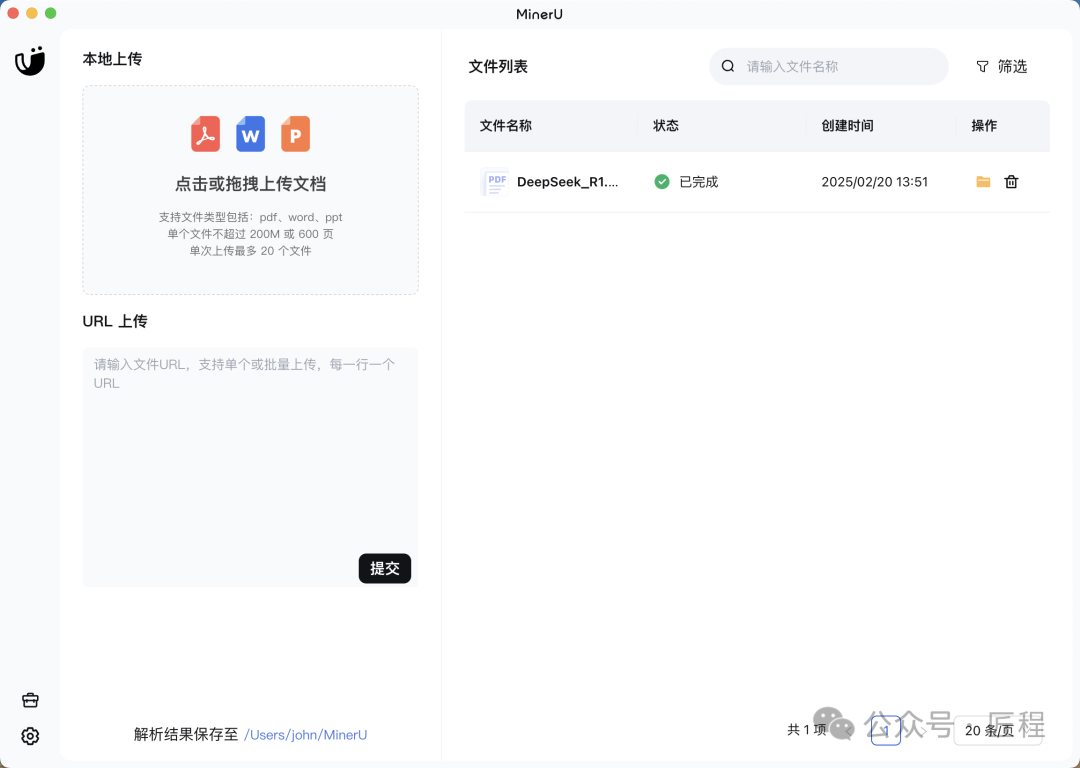
要经常用,不想写代码就下载客户端,支持Windows、Mac和Linux。拖拽文件就能转换。无需任何编程基础。客户端界面还能自由配置识别模式、语言等参数。
单次支持上传20个文件。下图是我转换DeepSeek-R1论文,公式识别相当准确。

方式二:本地部署版
这种方式灵活性更强,适合批量处理或自定义配置。
安装步骤:
- 首先创建Python环境:
conda create -n MinerU python=3.10conda activate MinerUpip install -U "magic-pdf[full]" --extra-index-url https://wheels.myhloli.com
-
下载必要的模型文件(参考官方教程)
-
调整配置文件(自动生成在用户目录下的magic-pdf.json)
- 可以开关特定功能,比如关闭公式识别来提速
- 可以选择不同的模型,比如切换表格识别模型
- 如果有GPU,可以设置device-mode来启用加速
如果你有显卡(8GB以上显存),建议用GPU版本,处理速度能提升10倍。Ubuntu和Windows用户参考对应的GPU加速教程配置CUDA环境。
Mac的M系列芯片用户可以通过设置"device-mode": "mps"启用加速。
方式三:Docker快速部署
喜欢用Docker的话,一条命令搞定:
docker run --rm --gpus=all mineru:latest
注意这个版本需要GPU支持。
选择建议:
- • 偶尔用就装桌面版,简单省事
- • 要经常处理文档,用本地部署版,可以根据需求调优
- • 团队使用推荐Docker版,环境统一好维护
记得第一次使用都要下载模型文件,官方文档有详细说明。
4
不过要提醒一下,虽然它是免费开源的,它用了AGPL协议,商业使用前要留意许可条款。
有了这个工具,不管是建知识库还是准备训练数据都方便太多了。
平时处理几百篇文献的工作量,现在很短时间就搞定。
如果你正在寻找一个可靠的文档转换工具,不妨试试这个被称为"大模型时代文档转换神器"的工具!
参考资料
项目地址:https://github.com/opendatalab/MinerU
如果你想用AI优化工作流,想用AI放大生产力
欢迎找我们聊聊(微信:a52947593)
相关文章
PydanticIA+CrawlAI:一键将任何网站转化为AI知识库
高效获取数据
2025/3/1免费开源的pdf转md工具,这几款帮了大忙
在AI时代,我们经常需要把PDF文档喂给ChatGPT或Claude这样的大语言模型。 但直接复制粘贴PDF内容往往一团糟:格式错乱、引用标注到处都是、公式变成乱码。这时候,一个好的PDF转Markdown工具就成了刚需。 为什么需要转换成...
2026/1/11谷歌最新开源利器:把杂乱文本变成结构化数据,还能生成可视化页面,标出原文出处
LangExtract能让大语言模型(LLM)帮你从文本里提取想要的内容
2025/8/7RTranslator:不用联网,连上蓝牙就能和各国人无障碍交流
本地AI同传
2025/2/19