Anthropic企业服务实战经验:AI 落地不是安装聊天机器人,这三大错误最常见
2025年2月25日
你是否也被各种 AI 营销宣传轰炸得晕头转向?——"装个聊天机器人就能提升效率 50%!""只要做个摘要功能,立刻节省 30% 成本!"
听起来是不是特别诱人?但现实可能没那么简单。
最近,Anthropic 公司的技术团队成员 Alexander Bricken 和企业 GTM 负责人 Joe Bailey 分享了他们帮助数百家企业落地 AI 的经验。

他们在AI落地上的探索走在前列,分享的内容干货满满。值得我们学习。
以下是基于他们的分享整理梳理的内容。
先介绍下 Anthropic
Anthropic 是一家专注于 AI 安全和研究的公司,由一群 AI 领域的顶级专家创立。
其明星产品是被誉为"最有人情味"的 Claude 大语言模型。最新的 Claude 3.5 Sonnet 模型在代码领域表现尤为出色。
该公司最大特点是对"模型可解释性"的追求——通过"逆向工程"方式理解 AI 模型的"思考"过程。
他们想通过某种"逆向工程"方式,弄清楚这些 AI 模型到底是怎么"思考"的,以及为什么会这样"思考"。
现在这项研究还处于早期阶段,可能只完成了前 25% 的工作,但已经按照"理解→检测→引导→可解释性"四个阶段在稳步推进。
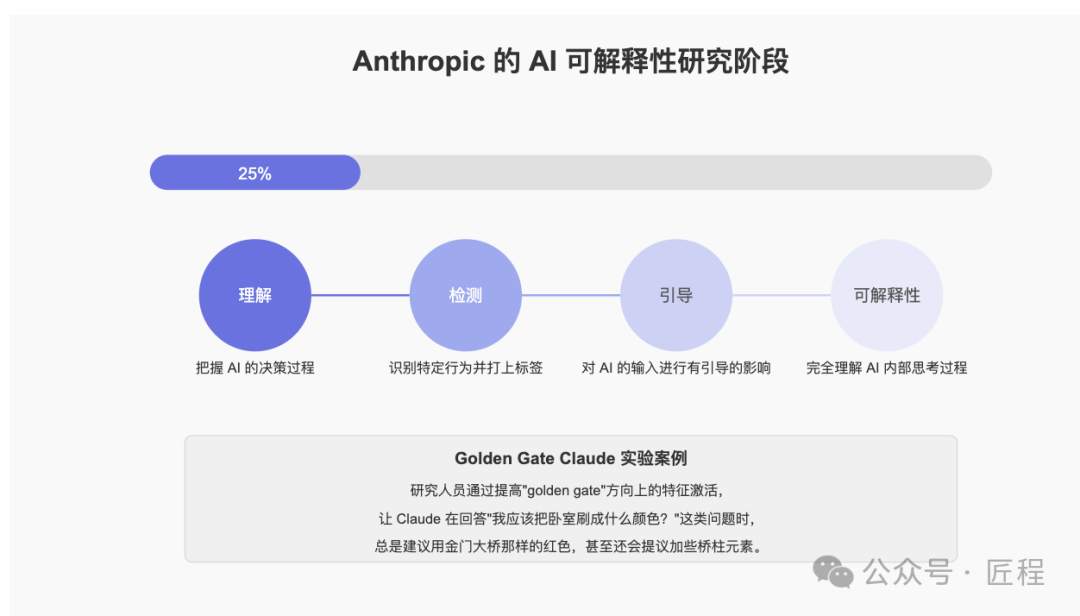
举个有趣的例子,他们通过提高"golden gate"方向上的特征激活,让 Claude 在回答"我应该把卧室刷成什么颜色?"
这类问题时,总是建议用金门大桥那样的红色,甚至还会提议加些桥柱元素。
这证明,我们有可能引导模型朝特定方向思考,而不仅仅是被动接受它的输出。
不要被噪音迷惑,要回到业务问题
当前市场充斥各种 AI 噪音。
许多公司盲目跟风,却没思考核心问题:AI 如何解决公司业务发展问题?
假设你做了一个求职平台,帮助用户提升职场技能。如果只做个简单的聊天机器人,客户用一次后,可能就再也不用这个平台了。
但如果你能用 AI 为每个用户提供高度个性化的课程,并且还可以根据学习进度动态调整难度。
或者为习惯看图片的学习者,自动生成可视化内容,那价值就完全不同了。
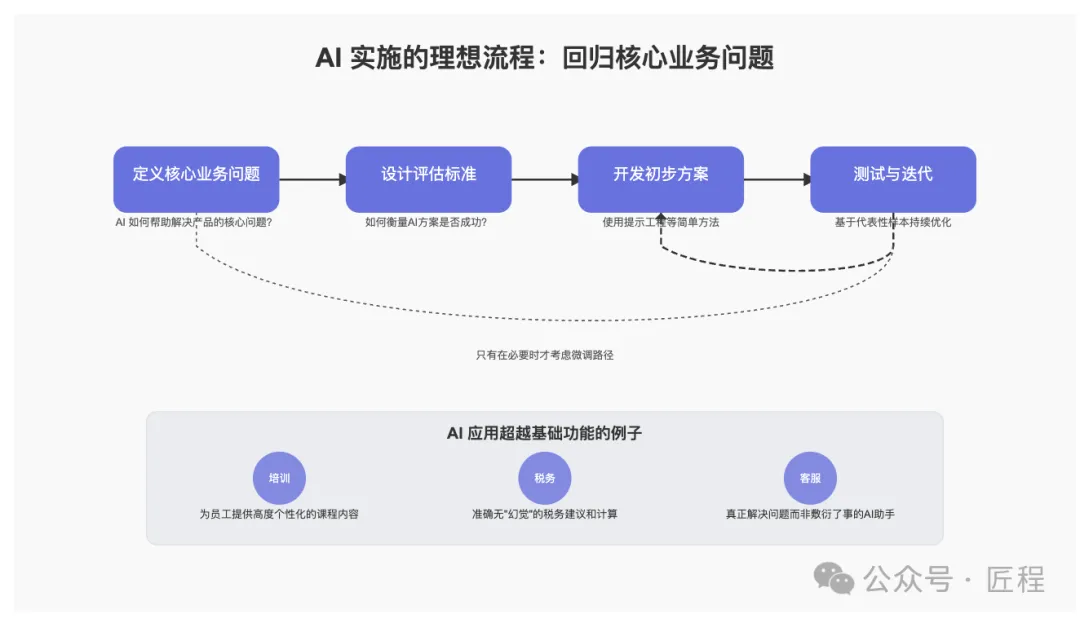
Joe 还分享了在税务、法律、项目管理等领域的成功案例。
这些在企业成功运用AI的都有一些共同特性:深入思考如何用 AI 大幅提升客户体验,让产品更易用、更可信,从而在业务关键工作流程中创造真正的价值。
这些企业结合了在领域内的专业积淀,以及大模型能力,特别是在税务等对"幻觉"容忍度低的场景,确保输出高质量且可靠。
下面再举一个例子。
案例:客服平台借助AI更有人情味?
Intercom 这家公司拥有一个叫做 Fin 的 AI 客服平台,他们希望借助大模型提升AI客服能力。

于是,Anthropic 和 Intercom 合作进行了一个为期两周的小测试:把最棘手的提示词放到 Claude 模型上做测试,并让AI优化提示词。
经过两个月,他们优化了所有与 Fin 相关的提示词。
最终的结果是,升级后的 Fin 可处理高达 86% 的客服需求,其中 51% 无需人工介入!
同时,Fin 也变得更加"有人情味",能根据需要调整语气和回答长度,甚至能准确识别与各种政策相关的问题(如退款政策)。

企业落地 AI 的三大常见错误
Alex分享了他们反复看到的最佳实践和常见错误,这些经验来自数百次与客户的真实互动。
错误一:先设计复杂流程,最后才评估效果
很多企业会先花大量时间设计流程和架构,最后才评估效果。
但这完全是本末倒置!
没有评估,你根本无法确定设计的工作流,是否真的适合企业,哪些环节可以借助AI优化。
错误二:只靠"直觉"或缺乏代表性样本
有些客户因为数据问题,不知道如何做评估。
有些干脆靠"直觉",测试几次感觉"好像不错"就盲目自信了。
但问题是,你测试的样本具有代表性吗?样本量足够吗?是否可以在统计上证明结果可靠?
如果进入生产环境后,有成百上千种情况出现差错,你之前的几次测试可能完全捕捉不到这些案例。
Alex 建议把用例想象成一个"潜在空间",你在这个空间里尝试不同方法(提示工程、提示缓存等),这些方法会改变模型的注意力机制,结果大不相同。
唯一能确定效果的方式是通过实证测试。谁能在这个潜在空间里通过评估更快地找到最优解,谁就能取得竞争优势。
要做到这一点,就需要有完善的监控系统来回放测试结果,确保收集了有代表性的测试用例。
就像在客服场景中,你可能会遇到一个小孩问"我在《我的世界》里怎样打僵尸?"
虽然完全与你的产品无关,但这种情况确实可能发生,所以也要看看模型会如何处理这类问题。
错误三:盲目迷信微调
许多客户一开始就要求微调自己的大模型。
但是微调并不是万能。微调就像对模型做"脑外科手术",可能会影响模型在其他领域的推理能力。
更糟糕的是,很多客户在评估集都没准备好的情况下就想着微调大模型。
但他们根本不知道为什么要微调。
如果只有微调才能达到成效,再考虑也不迟。
在进行微调大模型前,可以先尝试其他方法,比如提示工程、提示缓存、更高效的检索机制等。
只有在确实需要微调时才考虑引入。
毕竟,微调效果也不一定能保证,微调带来的收益能够覆盖成本时,才有微调价值。
如何权衡关键指标?
在实际应用中,常常需要权衡"智能度、成本、延迟"。
大多数企业只能重点优化1-2个,很难把三者都做到极致,不同的用例其侧重点也不同。
比如,如果你做的事AI客服,你希望顾客 10 秒内能收到回复,否则他就走了,甚至可能到处吐槽你的服务。
但如果你做的是金融研究员的AI助手,可能等待 10 分钟也无所谓,毕竟要做的是资金分配决策。
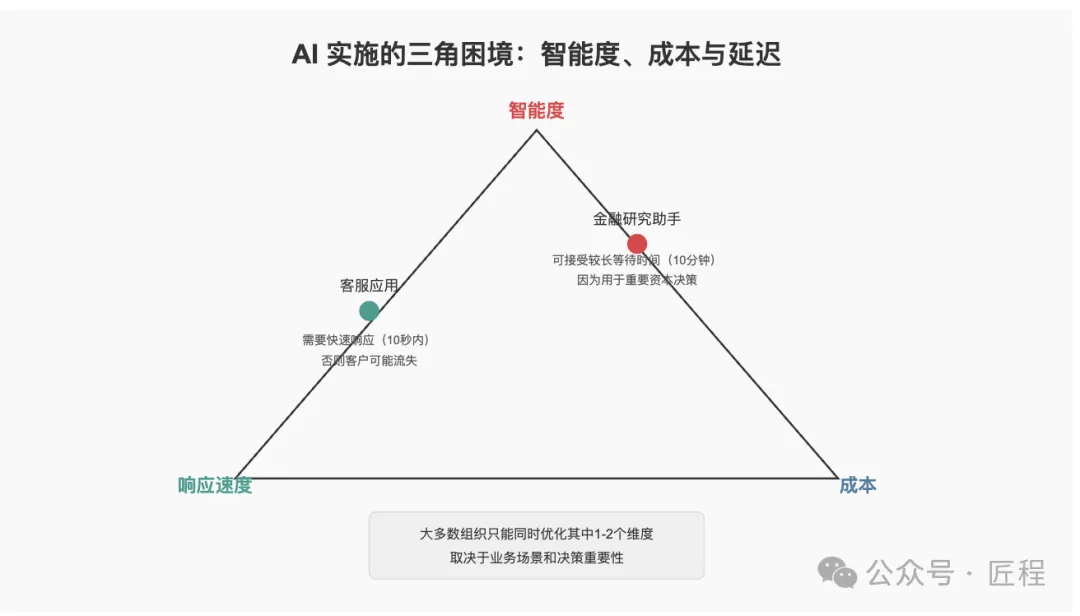
所以不同的决策时效性和重要性决定了你如何在这三者之间取舍。
有时可以通过一些用户体验设计,解决这些问题。比如在等待时显示"思考中"的动画,或引导用户先浏览其他内容。
但你仍然需要明确关键指标是什么,并据此做技术或设计层面的优化。
AI在企业落地,远非安装聊天机器人那么简单。而是需要回归业务本质,解决实际问题。
目前企业场景落地AI的案例并不多,大部分还在探索阶段。
希望上面的分享,能给你带来启发。
注:上文图片由Claude制作。
相关文章
Anthropic产品经理:我是如何管理项目的?
项目管理经验
2025/3/18银行进行私有部署的六大优势
六大优势
2024/12/28免费下书+AI陪读,这个开源工具绝了
下载电子书后直接问AI\"这书讲了啥\",现在真能做到。 一个开源项目,从Z-Library(全球最大的免费电子书库)下书,自动上传到Google NotebookLM(AI笔记工具),然后你就能和书对话。问\"第三章在说什么\"\"作者的核心论点是...
2026/1/22AI 让科研效率提升百倍?我看了 Anthropic 的最新报告后惊了
上周读到 Anthropic 发布的一篇科研应用案例(原文见最后),里面提到斯坦福大学的研究团队用 AI 把原本需要数月的基因研究压缩到 20 分钟。我第一反应是:又来吹牛? 但仔细看完麻省理工、斯坦福这些顶尖实验室的具体数据后,我发现这不...
2026/1/20