基于浏览器的图形RAG与Kuzu-Wasm:构建隐私优先的LinkedIn数据聊天机器人
2025年3月10日
Chang Liu:DevOps 工程师 、Kùzu Inc. 联合创始人 Semih Salihoğlu
Semih Salihoğlu:Kùzu Inc. 首席执行官 & 滑铁卢大学副教授
2025年3月10日 示例 我们很高兴地看到我们社区的成员已经开始使用 Kuzu 的 WebAssembly (Wasm) 版本构建应用程序,该版本仅在几周前发布!
早期采用者包括阿里巴巴的 Graphscope,其项目即将上线。
在这篇文章中,我们将展示 Kuzu-Wasm 的潜力,通过构建一个完全在浏览器中运行的聊天机器人,该机器人使用一种先进的检索技术:图形检索增强生成 (Graph RAG) 来回答 LinkedIn 数据上的问题。
这是通过 Kuzu-Wasm 和 WebLLM 实现的,后者是一个流行的浏览器内 LLM 推理引擎,可以在浏览器中运行 LLM。
WebAssembly 简介
WebAssembly (Wasm) 已将浏览器转变为通用计算平台。许多基础软件组件,如完整的数据库、机器学习库、数据可视化工具以及加密/解密库,现在都有 Wasm 版本。这使得开发者能够构建完全在用户浏览器中运行的高级应用程序——无需后端服务器。构建完全基于浏览器的应用程序有几个好处:
- 隐私: 用户的数据永远不会离开他们的设备,确保了完全的隐私和机密性。
- 易于部署: 基于浏览器的应用程序使用基于Wasm的组件,可以在任何浏览器中以完全无服务器的方式运行。
- 速度: 消除前端与服务器之间的通信可以显著提高用户体验的速度和互动性。
考虑到这一点,让我们展示如何在浏览器中完全开发一个相对复杂的AI应用程序!我们将构建一个完全在浏览器中运行的聊天机器人,使用图检索增强生成(Graph RAG)来回答自然语言问题。我们将使用Kuzu-Wasm和WebLLM来演示这一点。
架构
该应用程序的高层架构如下所示:
“Graph RAG”一词用于指代几种技术,但在其最简单的形式中,该术语指的是一种三步检索方法。其目标是从图形数据库管理系统(GDBMS)中检索有用的上下文,以帮助大型语言模型(LLM)回答自然语言问题。
在我们的应用程序中,附加数据是关于用户LinkedIn数据的信息,包括他们的联系人、消息,以及用户或其联系人曾工作的公司。是的,你可以下载自己的LinkedIn数据(如果没有其他原因,至少应该看看他们拥有多少你的数据!)。
我们用来建模这些数据的图数据库的架构将在下面展示。首先,让我们回顾一下Graph RAG的三个步骤:
- Q N L _{NL} N L → \rightarrow → Q C y p h e r _{Cypher} C y p h er : 用户提出一个自然语言问题 Q N L _{NL} N L ,例如“ 我的哪些联系人在谷歌工作?”。然后,使用一个大型语言模型(LLM),这个问题被转换为一个 Cypher 查询,例如
MATCH (a:Company)<-[:WorksAt]-(b:Contact) WHERE a.name = "Google" RETURN b,旨在检索存储在 GDBMS 中的相关数据以回答这个问题。 - Q C y p h e r _{Cypher} C y p h er → \rightarrow → 上下文:Q C y p h e r _{Cypher} C y p h er 在 GBMS 中执行,并检索到一组记录,例如“Karen”和“Alice”。我们将这些检索到的记录称为“上下文”。
- (Q N L _{NL} N L + 上下文) → \rightarrow → A N L _{NL} N L : 最后,原始的 Q N L _{NL} N L 与检索到的上下文一起提供给 LLM,LLM 生成一个自然语言答案 A N L _{NL} N L ,例如“ Karen 和 Alice 在谷歌工作。”
实施
数据摄取
我们个人 LinkedIn 数据图的架构如下所示:
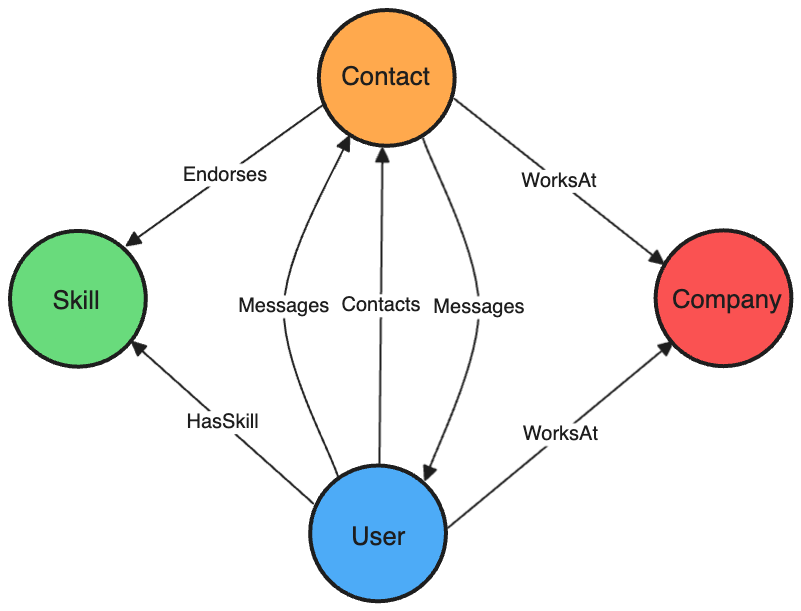
我们通过几个步骤将数据摄取到 Kuzu-Wasm 中,使用自定义的 JavaScript 代码(请参见我们 GitHub 仓库中的 src/utils/LinkedInDataConverter.js 文件):
- 上传 CSV 文件:用户拖放他们的 LinkedIn CSV 文件,这些文件存储在 Kuzu-Wasm 的虚拟文件系统中。
- 初步处理:使用 Kuzu 的
LOAD FROMfeature,将原始 CSV 转换为 JavaScript 对象。 - 标准化:在 JavaScript 中,我们通过修复时间戳、格式化日期和解决不一致的 URI 来清理和标准化数据。
- 数据插入:清理后的数据作为一组节点和关系插入回 Kuzu-Wasm 中。
WebLLM 提示
我们的代码遵循上述的三个步骤。具体来说,我们对WebLLM进行了两次提示,第一次是创建一个Cypher查询 QCypher_{Cypher}Cypher,该查询被发送到Kuzu-Wasm。
我们从LangChain-Kuzu集成中调整了提示,并进行了少量修改。重要的是,我们确保在提示中包含Kuzu的LinkedIn数据库的模式信息,这有助于LLM更好地理解数据集中的结构和关系(包括关系的方向性)。
在这个例子中,我们将模式表示为YAML,而不是在LLM提示中使用原始的字符串化JSON。根据我们的经验,对于需要对模式进行推理的文本到Cypher任务,我们发现LLM在处理YAML语法时表现得比处理字符串化JSON更好。
关于此类文本到Cypher任务的更多实验将在未来的博客文章中展示。
观察
看到这样一个完全在浏览器中实现的基于图的管道与LLMs结合,确实令人印象深刻!
然而,也有一些注意事项。最重要的是,在浏览器中,资源是有限的,这限制了应用程序不同组件的大小。
例如,您可以使用的LLM的大小是有限的。我们在2023年的MacBook Pro和Chrome浏览器上测试了我们的实现。我们不得不选择Llama-3.1-8B-Instruct-q4f32_1-MLC模型(有关模型卡,请参见这里),这是一个以MLC格式调优的指令模型。
q4f32_1格式是Llama 3.1模型中参数为8B的最小模型(最大模型有450B参数,当然在浏览器中运行太大了)。对于简单的查询,该模型表现相当不错。它正确生成了LinkedIn数据的Cypher查询,例如:
- 我关注了多少家公司?
- 哪些联系人在 Kùzu, Inc 工作?
- 我拥有哪些技能?
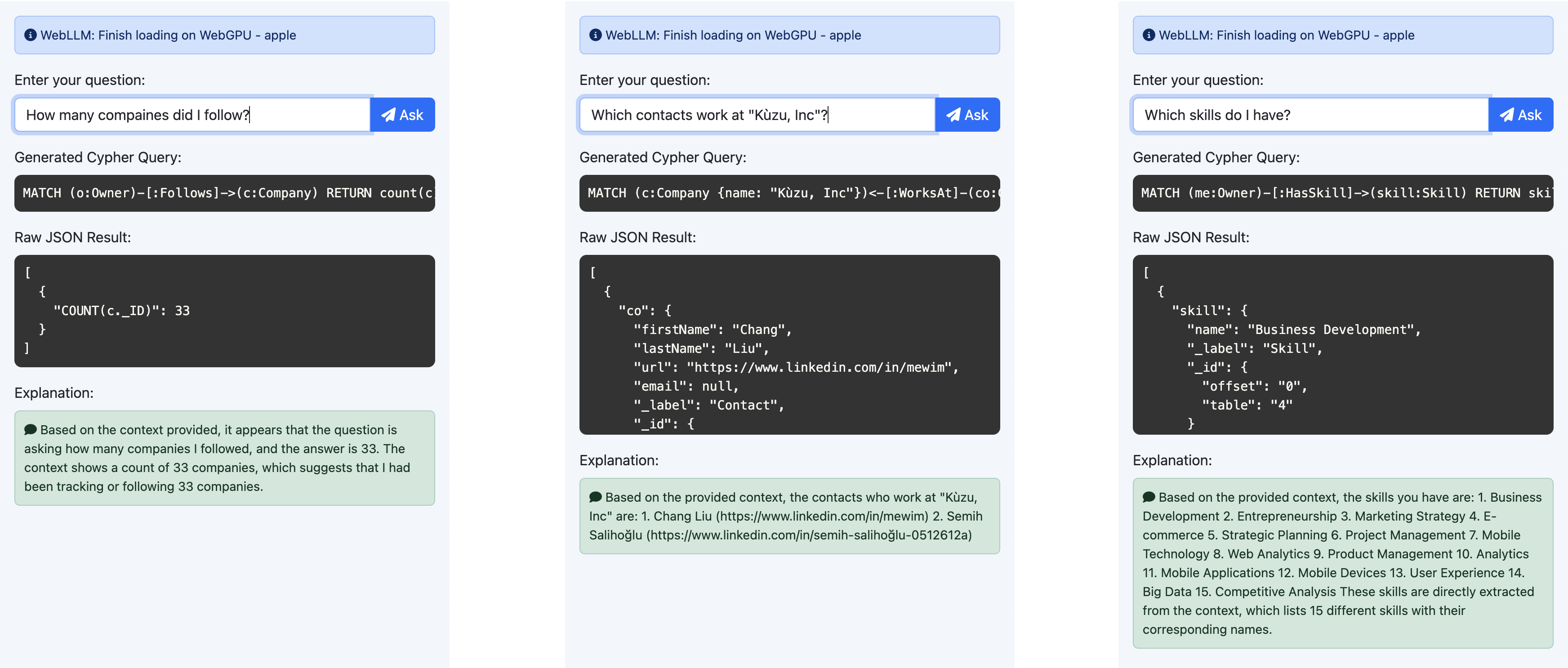
然而,我们发现对于需要连接、过滤和聚合的更复杂查询,模型在返回有效的 Cypher 查询时表现不佳。 它经常为诸如“谁最常支持我?”这样的问题生成不正确或不完整的 Cypher 查询。
令牌生成的速度也远低于您在先进接口(如 ChatGPT)中可能习惯的速度。
在我们的实验中,我们观察到速度为每秒 15-20 个令牌,因此生成答案平均需要大约 10 秒。
现场演示
我们已部署此演示,您可以在浏览器中进行测试:
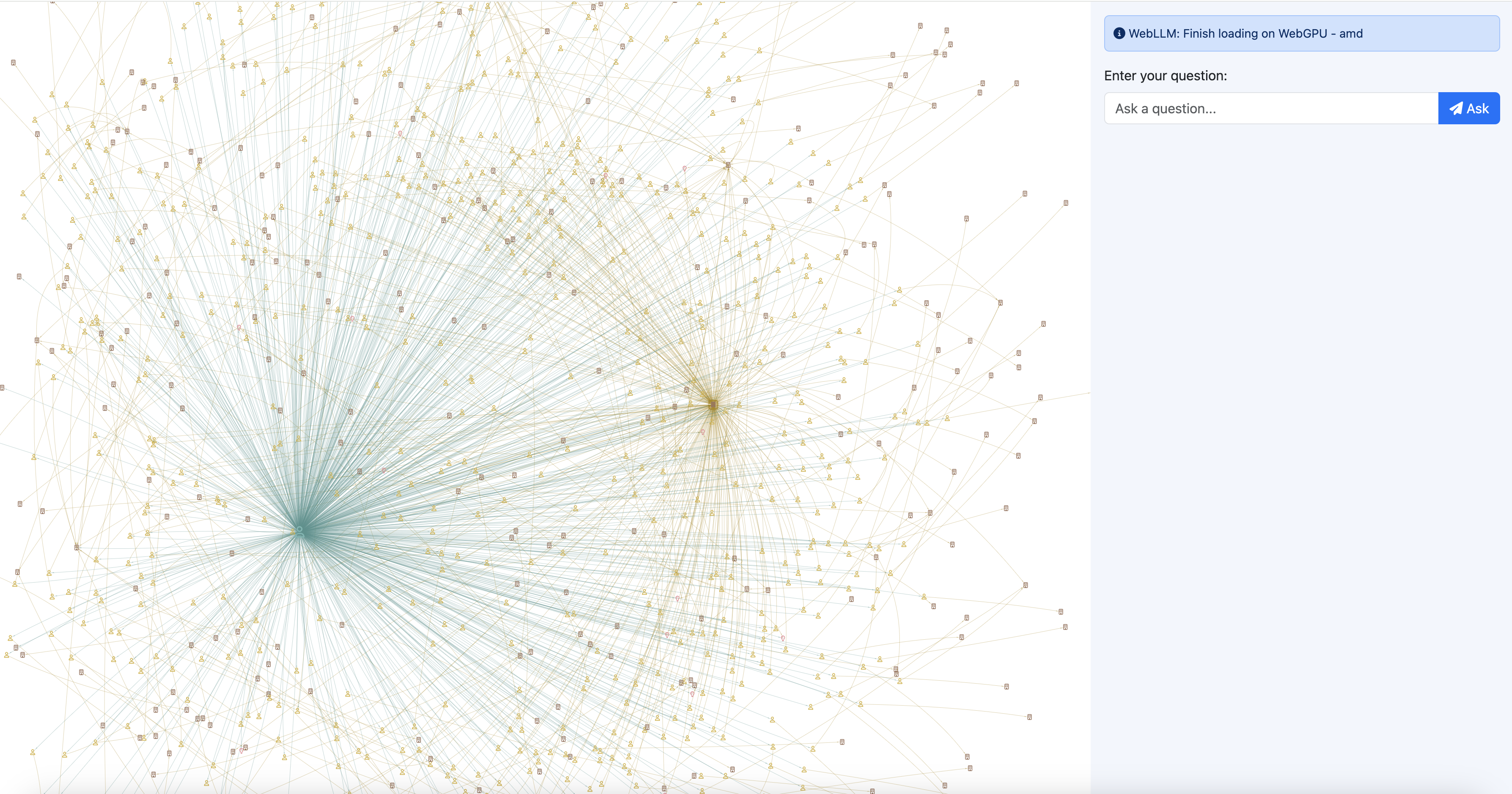
- 现场演示:将您的 LinkedIn 数据导出 拖放到应用程序中,开始查询您的个人图谱。该演示还使用
vis.js以节点-链接图的形式可视化您的数据。 - GitHub 仓库:源代码是公开可用的,您可以进一步进行实验。如果您在不同的模型/提示下看到更好的结果,我们非常希望听到您的反馈!
一旦数据加载完成,您将看到类似于以下的可视化效果:
关键要点
本篇文章的关键要点是,利用图数据库和大型语言模型(LLMs)的先进管道现在可以完全在浏览器中实现。
我们预计,随着WebGPU、Wasm64及其他改进Wasm的提案的广泛采用,今天的许多性能限制将会随着时间的推移而改善。LLMs也在迅速变得更小更好,不久之后,就可以在浏览器中使用非常先进的LLMs。
Kuzu的下一个版本将包括一个原生向量索引(它已经在我们的夜间构建中可用;请查看这个PR了解如何使用它!)。因此,您还可以存储文档的嵌入以及实际的节点和关系记录,以增强您的图形检索,完全在Kuzu内部。使用我们即将推出的向量索引,您将能够尝试各种有趣的RAG技术,结合Kuzu-Wasm,所有这些都可以在浏览器中进行,同时保持您的数据私密。前景无限!