在 PostgreSQL 中用 ColBERT 重排序让向量搜索更快更准!
2025年1月28日
传统的向量搜索方法通常使用句子嵌入来定位相似内容。然而,通过对标记嵌入进行池化生成句子嵌入可能会牺牲标记级别的细粒度细节。ColBERT 通过将文本表示为标记级别的多向量而不是单一的聚合向量来克服这一问题。
这种方法利用标记级别的上下文延迟交互,使 ColBERT 能够保留更细致的信息,并提高搜索准确性,相较于仅依赖句子嵌入的方法。
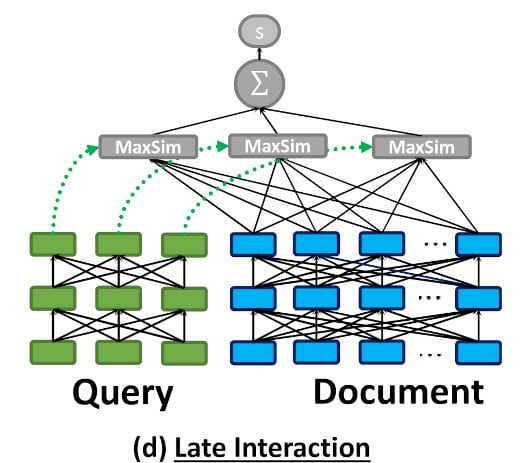
如上图所示,ColBERT 将每个文档/查询编码为一系列标记向量,并在查询时计算 MaxSim。
标记级别的延迟交互需要更多的计算能力和存储空间。这使得在大型数据集中使用 ColBERT 搜索变得具有挑战性,尤其是在低延迟至关重要的情况下。
一种可能的解决方案是将句子级向量搜索与标记级延迟交互重排序相结合,这利用了近似向量搜索的高效性和多向量相似性搜索的高质量。
多向量方法不仅限于纯文本检索任务;它还可以用于视觉文档理解。对于多模态检索模型,像 ColPali 和 ColQwen 这样的最先进模型直接将文档图像编码为多向量,并展示出比 OCR 到文本方法更强的性能。
本博客将展示如何使用PostgreSQL扩展VectorChord和pgvector与ColBERT重新排序。
教程
假设我们已经有了文档,让我们创建一个表来存储所有文档:
import psycopg
from pgvector.psycopg import register_vector
class PgClient:
def __init__(self, url: str, dataset: str, sentence_emb_dim: int, token_emb_dim: int):
self.dataset = dataset
self.sentence_emb_dim = sentence_emb_dim
self.token_emb_dim = token_emb_dim
self.conn = psycopg.connect(url, autocommit=True)
with self.conn.cursor() as cursor:
cursor.execute("CREATE EXTENSION IF NOT EXISTS vchord CASCADE;")
register_vector(self.conn)
def create(self):
with self.conn.cursor() as cursor:
cursor.execute(
f"CREATE TABLE IF NOT EXISTS {self.dataset}_corpus "
"(id INT BY DEFAULT AS IDENTITY PRIMARY KEY, text TEXT, "
f"emb vector({self.sentence_emb_dim}), embs vector({self.token_emb_dim})[]);"
)
在这里,我们创建了一个包含句子级嵌入和标记级嵌入的表。
有许多嵌入API和open-source models。您可以选择适合您用例的那一个。
对于标记级嵌入:
from colbert.infra import ColBERTConfig
from colbert.modeling.checkpoint import Checkpoint
class TokenEncoder:
def __init__(self):
self.config = ColBERTConfig(doc_maxlen=220, query_maxlen=32)
self.checkpoint = Checkpoint(
"colbert-ir/colbertv2.0", colbert_config=self.config, verbose=0
)
def encode_doc(self, doc: str):
return self.checkpoint.docFromText([doc], keep_dims=False)[0].numpy()
def encode_query(self, query: str):
return self.checkpoint.queryFromText([query])[0].numpy()
ColBERT模型默认生成128维向量。
插入数据的方法:
class PgClient:
...
def insert(self, documents: list[str]):
with self.conn.cursor() as cursor:
for doc in tqdm(documents):
sentence_emb = sentence_encoder.encode_doc(doc)
token_embs = [emb for emb in token_encoder.encode(doc)]
cursor.execute(
f"INSERT INTO {self.dataset}_corpus (text, emb, embs) VALUES (%s, %s, %s)"
(doc, sentence_emb, token_embs)
)
对于向量搜索部分,我们可以使用VectorChord构建高性能的RaBitQ索引:
class PgClient:
...
def index(self, num_doc: int, workers: int):
n_cluster = 1 << math.ceil(math.log2(num_doc ** 0.5 * 4))
config = f"""
residual_quantization = true
[build.internal]
lists = [{n_cluster}]
build_threads = {workers}
spherical_centroids = false
"""
with self.conn.cursor() as cursor:
cursor.execute(f"SET max_parallel_maintenance_workers TO {workers}")
cursor.execute(f"SET max_parallel_workers TO {workers}")
cursor.execute(
f"CREATE INDEX {self.dataset}_rabitq ON {self.dataset}_corpus USING "
f"vchordrq (emb vector_l2_ops) WITH (options = ${config}$)"
)
为了加快索引构建过程,我们可以利用外部质心构建。有关更多详细信息,请查看“Benefits and Steps of External Centroids Building in VectorChord”。
现在,我们可以查询PostgreSQL:
class PgClient:
...
def query(self, doc: str, topk: int):
sentence_emb = sentence_encoder.encode_query(doc)
with self.conn.cursor() as cursor:
cursor.execute(
f"SELECT id, text FROM {self.dataset}_corpus ORDER BY emb <-> %s LIMIT {topk}"
)
res = cursor.fetchall()
return res
为了支持MaxSim重新排序,我们需要创建一个函数:
class PgClient:
def __init__(self, url: str, dataset: str, sentence_emb_dim: int, token_emb_dim: int):
...
self.conn.execute("""
CREATE OR REPLACE FUNCTION max_sim(document vector[], query vector[]) RETURNS double precision AS $
WITH queries AS (
SELECT row_number() OVER () AS query_number, * FROM (SELECT unnest(query) AS query)
),
documents AS (
SELECT unnest(document) AS document
),
similarities AS (
SELECT query_number, document <=> query AS similarity FROM queries CROSS JOIN documents
),
max_similarities AS (
SELECT MAX(similarity) AS max_similarity FROM similarities GROUP BY query_number
)
SELECT SUM(max_similarity) FROM max_similarities
$ LANGUAGE SQL
""")
现在,我们可以对通过向量搜索检索到的文档进行重新排序:
class PgClient:
def rerank(self, query: str, ids: list[int], topk: int):
token_embs = [emb for emb in token_encoder.encode_query(query)]
with self.conn.cursor() as cursor:
cursor.execute(
f"SELECT id, text FROM {self.dataset}_corpus WHERE id = ANY(%s) ORDER BY "
f"max_sim(embs, %s) DESC LIMIT {topk}"
(ids, token_embs)
)
res = cursor.fetchall()
return res
评估
我们在多个BEIR数据集上测试了这种方法。以下是结果:
| 数据集 | 搜索 NDCG@10 | 重新排序 NDCG@10 |
|---|---|---|
| fiqa | 0.23211 | 0.3033 |
| quora | 0.31599 | 0.3934 |
这表明ColBERT重新排序可以显著提升向量搜索的结果。
所有相关的基准代码可以在here找到。
未来工作
使用ColBERT重新排序的向量搜索和全文搜索可以进一步提升性能。我们还在进行PostgreSQL BM25 extensions的相关工作,敬请关注。
参考文献
原文:点击这里
入群交流请联系:a52947593