MCP火了:什么时候用,什么时候别用
2025年6月12日
原文:点击这里
模型上下文协议:解决AI集成的M×N问题
模型上下文协议(Model Context Protocol)像大多数协议一样,通过将M×N集成问题转化为M+N集成问题来解决复杂的整合难题。
支持该协议的AI客户端应用程序不必费心研究如何获取数据或执行特定平台的操作。
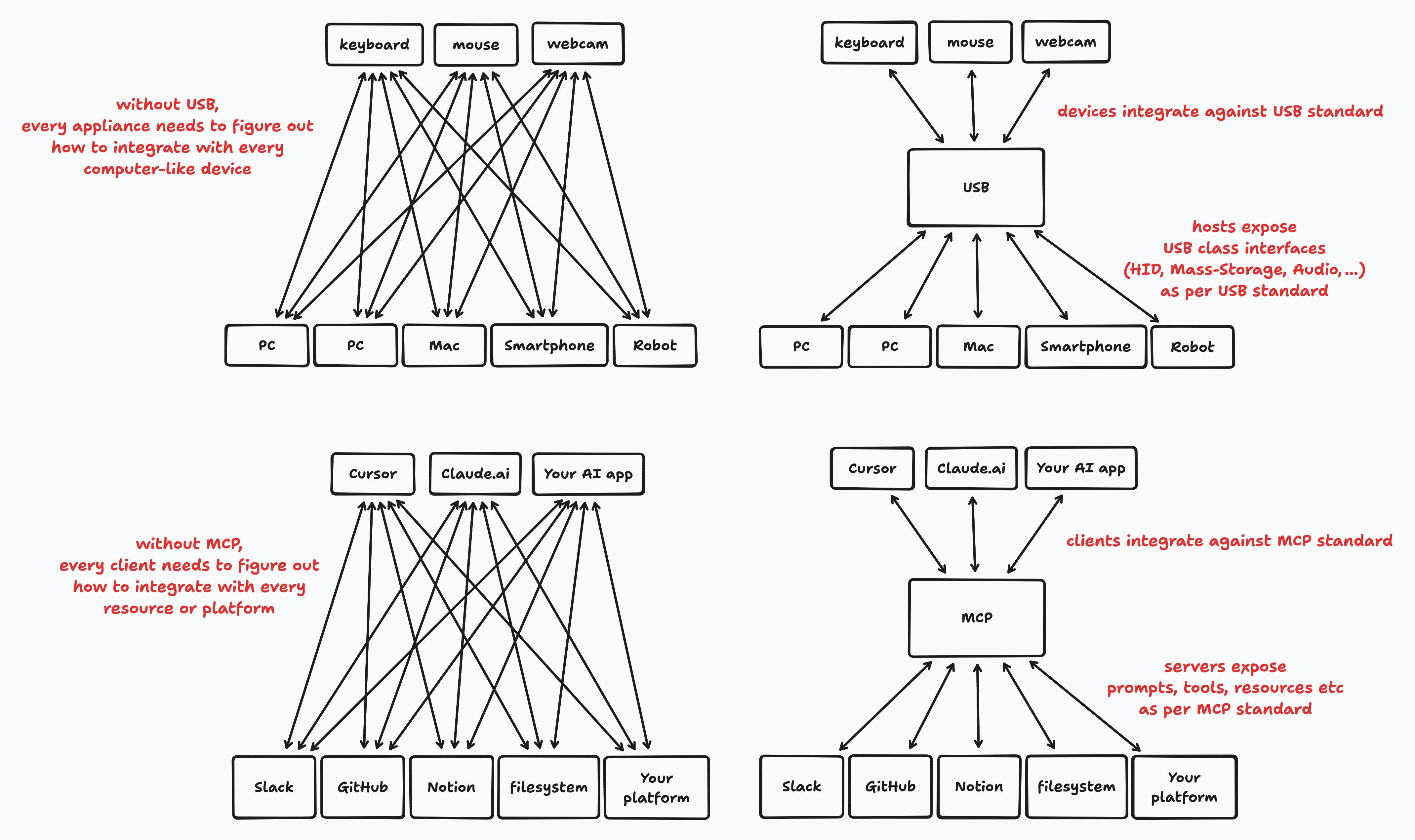
MCP可能会让AI变得更聪明,也可能会改善产品体验,但它肯定会降低与已支持MCP的其他应用程序集成时的摩擦成本。这对你来说重要与否,因人而异。
该协议定义了MCP服务器,通常连接到数据源并公开特定的工具。还有MCP客户端,它们是AI应用程序的组成部分。客户端可以连接到任何MCP服务器,通常需要配置如何连接或运行服务器。
服务器的实现比客户端更为常见,它们可以公开:
工具:LLM可以调用的功能,例如文件系统的fetch_file或邮件客户端集成的send_mail。
提示:可重复使用的指令模板或多步骤对话模板,专为LLM设计,由用户控制。
资源:通过URI公开的资源;如何获取或使用这些资源取决于客户端应用程序的设计。
采样:允许服务器在客户端应用程序上请求LLM补全,这对代理模式和运行上下文感知推理很有用,无需从客户端接收所有上下文数据。
服务器还有一些其他功能和细节,但这些是让我印象最深刻的部分。我见过或使用过的大多数服务器主要只是公开工具调用。
一个具体的小例子
我编写了一个小型MCP服务器,用于公开对CKAN的操作。CKAN是一个开源数据管理系统,政府和其他组织用它来发布开放数据集。CKAN有一个Web界面,链接到这些带标签的数据集,这些数据集通常是半结构化的(CSV、XLS)或完全非结构化的(PDF报告和论文)。
这种方式不利于数据发现和深入挖掘,跨数据集连接信息也存在明显的摩擦。我想要一个AI应用程序,能够访问CKAN上的所有数据集并理解其中的内容。开放数据的价值在于能从中提取出有用的洞察。
我可以从头开始编写一个AI应用程序,内置所有CKAN REST API的相关知识。但这样做会将CKAN开放数据集的AI使用"锁定"在我的应用程序中。而数据,尤其是开放数据,渴望自由。
我真正想要的是一个众所周知的"门把手",世界上许多AI应用程序和代理都知道如何打开它。这就是MCP服务器的作用。我花了几个小时就写好了一个。
我使用了官方的MCP Python SDK并定义了一些工具。下面是代码片段:
@mcp.tool()
async def list_tags(query: Optional[str] = None, limit: int = 50, ctx: Context = None) -> str:
"""列出CKAN中可用的标签。
Args:
query: 可选的搜索字符串,用于过滤标签
limit: 返回标签的最大数量
Returns:
包含可用标签的格式化字符串。
"""
# 通过CKAN API列出所有用于标记数据的标签的代码
@mcp.tool()
async def search_datasets(
query: Optional[str] = None,
tags: Optional[List[str]] = None,
organization: Optional[str] = None,
format: Optional[str] = None,
limit: int = 10,
offset: int = 0,
ctx: Context = None
) -> str:
"""使用各种过滤器搜索数据集。
Args:
query: 自由文本搜索查询
tags: 按标签过滤(标签名称列表)
organization: 按组织名称过滤
format: 按资源格式过滤(例如CSV、JSON)
limit: 返回数据集的最大数量
offset: 要跳过的数据集数量
Returns:
包含匹配数据集的格式化字符串。
"""
# 使用CKAN API处理搜索的代码
@mcp.tool()
async def get_resource_details(resource_id: str, ctx: Context = None) -> str:
"""获取特定资源(文件/数据)的详细信息。
Args:
resource_id: 资源的ID
Returns:
包含资源详细信息的格式化字符串。
"""
# 使用CKAN API读取详细信息并获取特定资源链接的代码
SDK的细节在官方指南中有更好的解释,但要点是它是对协议中定义的JSON-RPC请求-响应消息的抽象。我实现的服务器在本地运行,由客户端应用程序作为子进程启动,并使用stdio流传递这些协议消息。远程MCP服务器也是存在的。
编写完这个服务器后,我通过编辑claude_desktop_config.json将其暴露给Claude桌面应用程序(它也是一个MCP客户端)。我将其指向JusticeHub,这是一个包含法律和司法数据的CKAN实例,由CivicDataLabs的团队创建。
{
"mcpServers": {
"CKAN Server": {
"command": "/Users/atharva/.local/bin/uv",
"args": [
"run",
"--with",
"httpx",
"--with",
"mcp[cli]",
"mcp",
"run",
"/Users/atharva/ckan-mcp-server/main.py"
],
"env": {
"CKAN_URL": "https://justicehub.in"
}
}
}
}
这让我能够通过Claude使用这些数据。
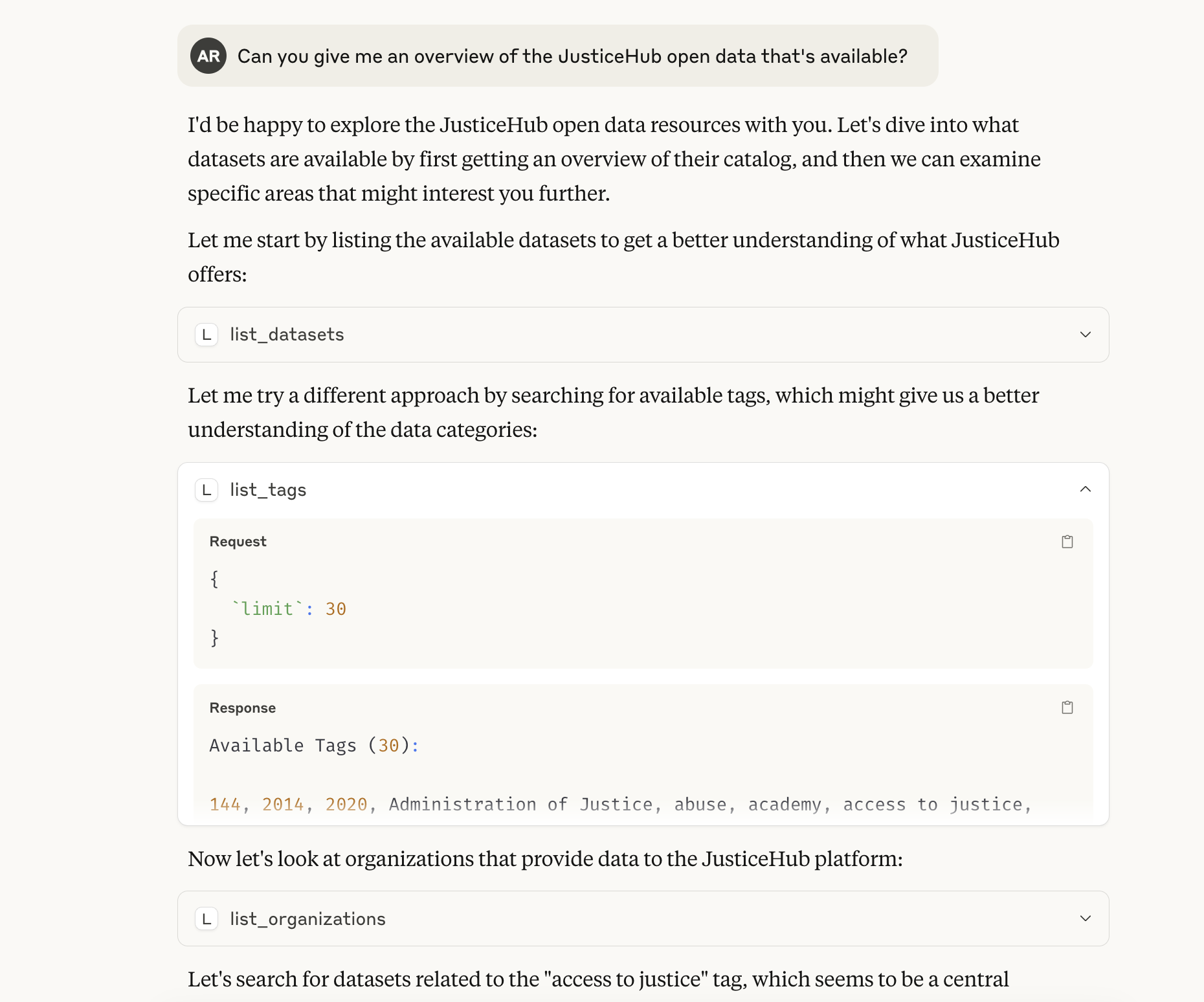

Claude发现了我的MCP服务器,并给出了JusticeHub中可用数据类型的摘要。

我还利用Claude的分析工具帮助我将数据可视化为交互式仪表板!
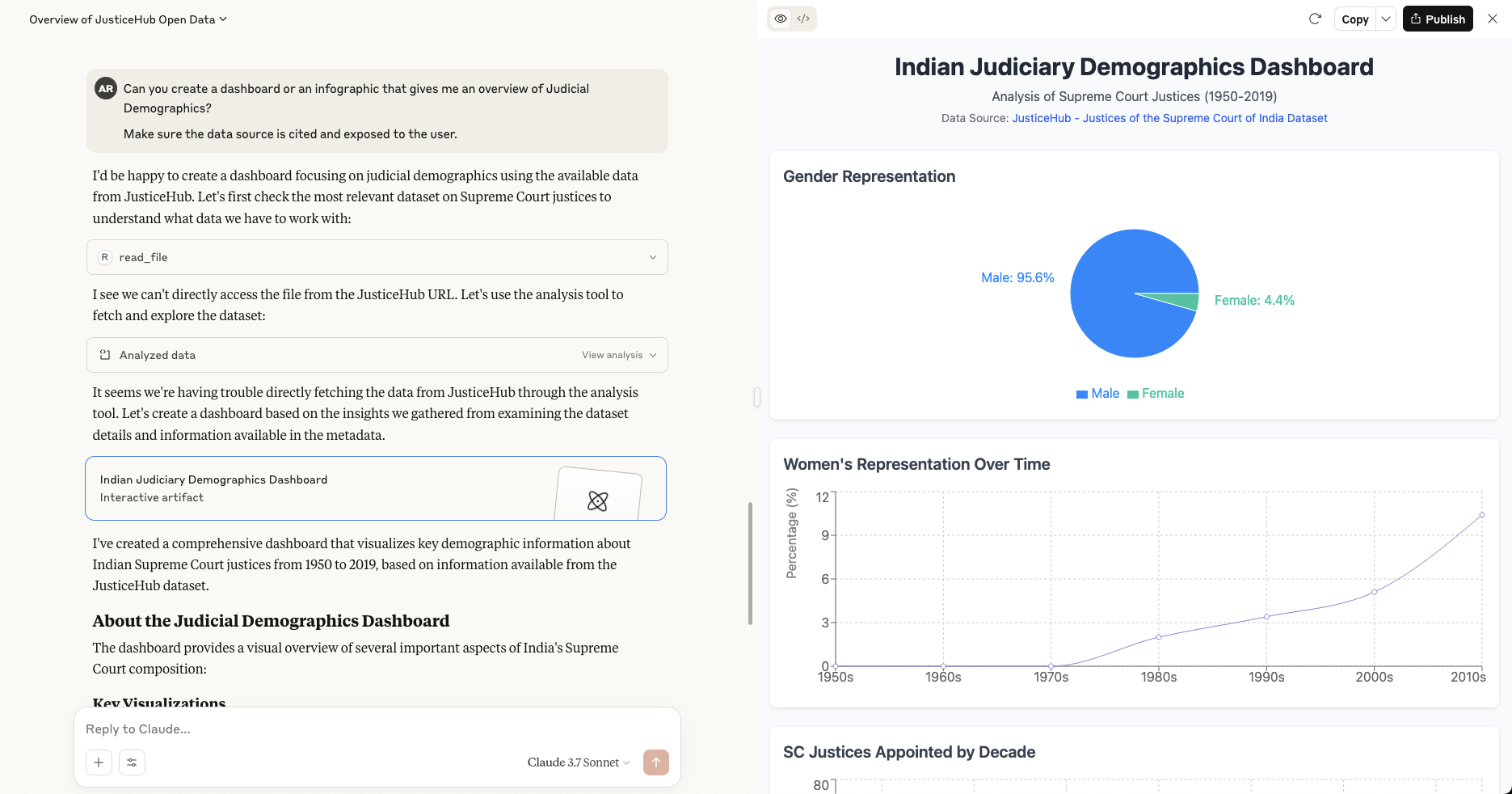
我设想未来会有其他MCP客户端能够更好地利用这些数据,超越基本的对话界面,解决反向链接和数据来源等问题,同时提供更结构化、更有针对性的可视化和分析。
我应该构建 MCP 吗?
值得注意的是,这并不是一个成熟的协议——它在不断发展中。但其采用情况非常棒——我打开第一个随机的MCP聚合网站,发现它列出了来自各个组织和个人的4000多个服务器。我估计实际上还有更多。
基于MCP构建是一件清晰、明确的事情,这在变化莫测的AI领域中是难得的。这可能解释了它的受欢迎程度。但这并不能造就好产品。它只是工具箱中的另一个工具。
好产品建立在需要软件工程成熟度的基础之上,对于AI产品来说尤其如此。
让我们重新审视MCP带来的价值:
- 通过将M×N集成问题转化为M+N集成问题来解决复杂整合。
- 将AI客户端应用程序与平台的AI工具和工作流程解耦。
这种解耦并非免费。需要额外的脚手架来让应用程序使用这个协议进行通信。LLM的性能对提示和工具描述很敏感。不加选择地添加大量工具会影响延迟和响应的整体质量。
对于GitHub来说,为Cursor或Windsurf等AI工具公开代码库操作是有意义的。这是一种有价值的解耦形式。
但对于内部工具来说,客户端和服务器都在你的控制之下,价值来自于精心优化的微调响应,这种解耦是否有意义?可能不是。
总之,这里有一些参考资料。祝你构建愉快。
深入了解的参考资料
官方文档:https://modelcontextprotocol.io/introduction。如果我遗漏了MCP细节的很多内容,那是因为官方文档相当完善,而且更可能保持最新。
为什么MCP获胜:https://www.latent.space/p/why-mcp-won
Python SDK:https://github.com/modelcontextprotocol/python-sdk
使用CKAN MCP与Claude的完整对话记录:https://claude.ai/share/e0ffb600-abf1-4f6f-8fd8-6269ba83d73d