推理能力不等同于实践经验:使用推理模型构建模块化RAG
2025年2月26日
搭建并维护一套强大的通用RAG系统绝非易事。影响输出质量的控制参数繁多,且彼此间交互复杂:
- 提示词模板
- 上下文窗口大小
- 查询扩展策略
- 文本切块方法
- 结果重排机制
- 等等
当系统更新或整合新模型时,重新校准这些参数对维持性能至关重要。然而,这不仅耗时,还需要丰富的专业经验才能调校得当。
DeepSeek-R1和OpenAI的o3-mini等新型推理模型通过内置的思维链(CoT)提示成效显著。
这些模型设计为能够分步"思考"问题并在必要时自我纠正。据报道,它们在需要逻辑推理且答案可验证的复杂问题上表现更为出色。
于是我们思考:**如果推理模型能够分解复杂问题并自我纠正,我们能否将其应用到RAG流程中的查询扩展、文档检索和重排序等环节?**通过构建信息检索工具集并交由推理模型操作,我们或许能打造一个更具适应性的系统,减少人工调参的需求。
这种方法有时被称为模块化RAG。
本文将分享我们近期研究中,将标准RAG流程重构为基于推理模型架构所获得的发现。
研究假设
探索这一思路的主要动机是检验它能否简化流程,减少人工参数调优的需求。RAG系统的核心组件是密集向量嵌入和文档检索。典型的高级RAG流程通常包括:
- 接收用户查询
- 预处理查询以优化信息检索效果
- 通过向量数据库中的相似度搜索定位相关文档
- 重新排序结果并选用最相关的文档
- 生成回复内容
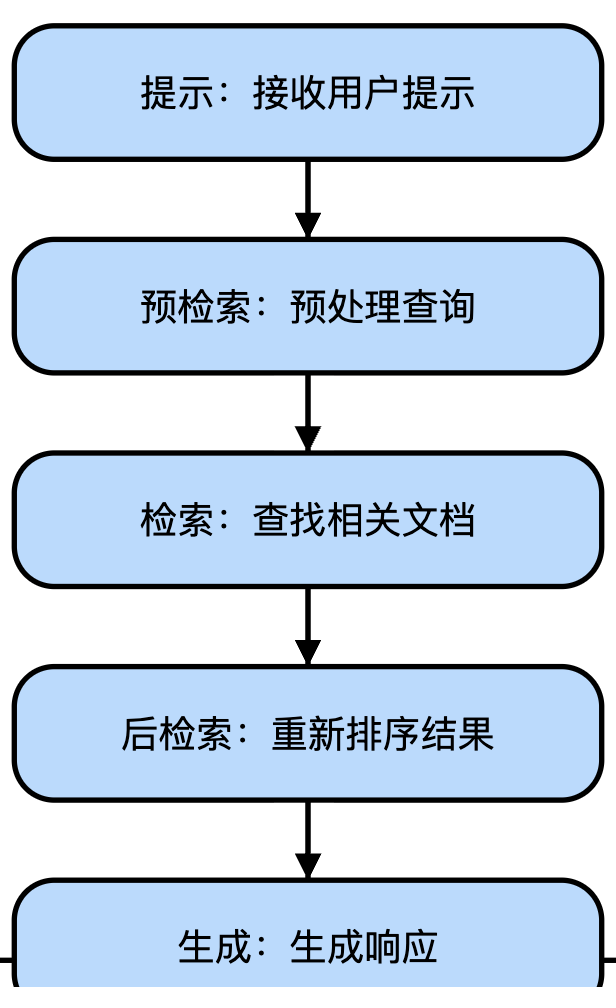
流程中每个环节都通过启发式算法进行优化,如过滤规则和排序调整,以优先处理相关信息。这些硬编码的优化虽然定义了流程行为,但也限制了其适应性。
为了让推理模型能够调用我们流程中的组件,我们需要采取不同的设计方式。我们不再定义线性步骤序列,而是将每个组件设计为模型可独立调用的功能模块。
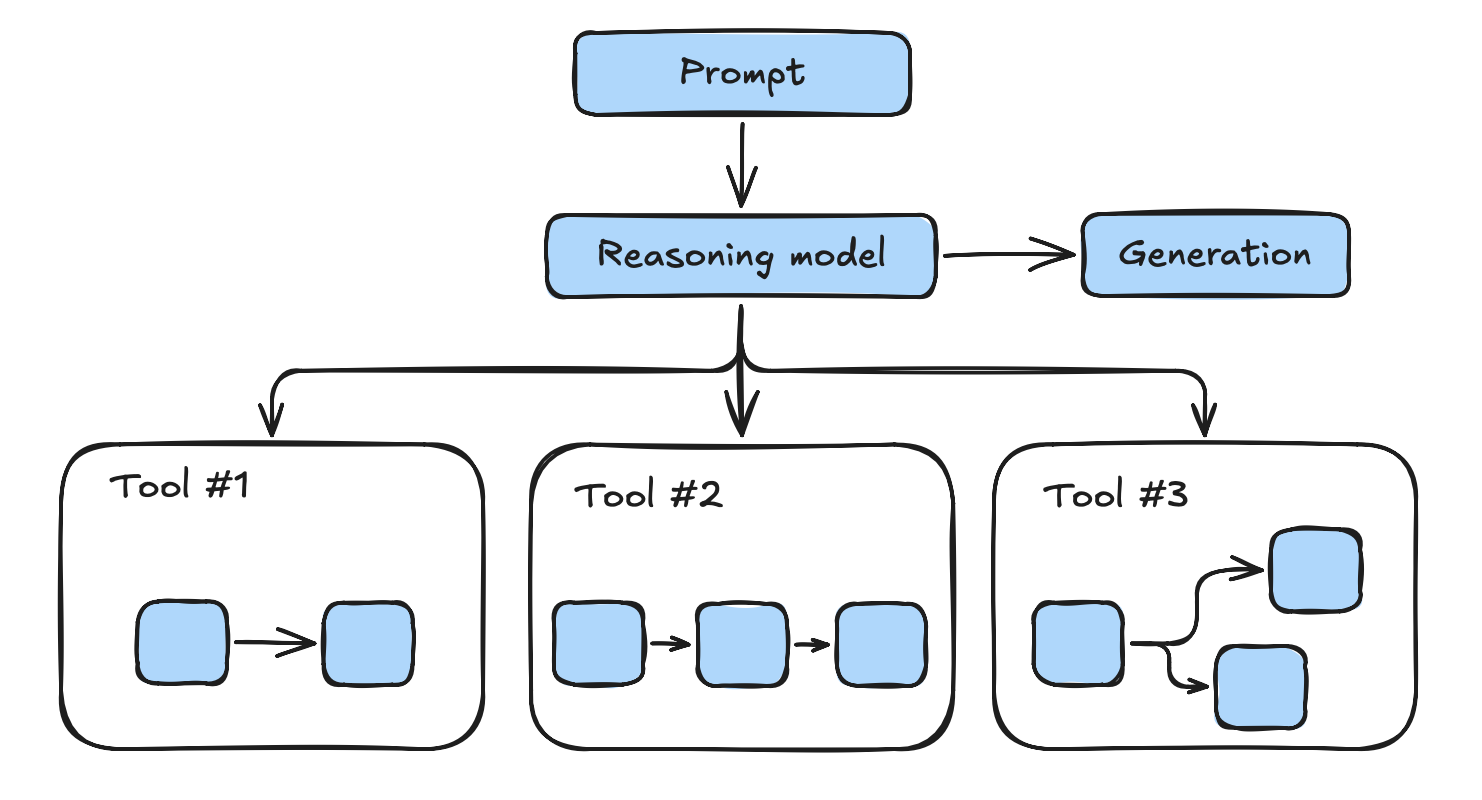
在这种架构下,具备推理能力的模型不再遵循固定流程,而是能更灵活地控制自身工作流。通过工具调用机制,模型可以自主决定何时以及多频繁地执行完整检索或简化检索,并自行确定检索参数。若此方法成功,它可能取代LangGraph等传统RAG编排框架。
此外,更模块化的系统还可能带来多项额外优势:
- 单个模块可独立替换或升级,无需重构整个系统
- 职责划分更明确,使调试和测试更加便捷
- 不同模块(如采用不同嵌入方式的检索器)可进行对比测试和替换
- 各模块可针对不同数据源独立扩展
- 有可能开发针对特定任务或领域的专用模块
最后,我们想探索的另一个应用场景是这种方法能否帮助我们更高效地"短路"处理滥用或离题查询。最棘手的情况往往存在模糊地带,难以判断查询是否与产品相关。滥用性查询通常经过精心设计以逃避检测。虽然简单情况已能有效处理,但我们希望推理模型能够识别更复杂的问题并及早中止无效对话。
测试设置
为了验证这种工作流,我们搭建了一个沙盒RAG系统,包含必要组件、静态数据和基于LLM的评估框架。在一种配置中,我们采用了内置硬编码优化的传统线性流程。
对于以o3-mini为推理核心的模块化RAG流程,我们在不同策略下测试了多种配置以评估效果:
- 工具使用策略:我们尝试了赋予模型完全访问所有工具和整个流程的权限,也尝试将工具使用限制为单一工具结合固定线性流程
- 提示词设计和参数化方法:我们测试了从最小指令的开放式提示到高度结构化的提示等不同方案。我们还实验了各种程度的预设参数工具调用与让模型自行决定参数的方法
所有测试中,我们将工具调用次数上限设为20次——对任何查询,模型最多只能进行20次工具调用。我们还在中等和高强度推理模式下运行所有测试:
- 中等强度:较短的思维链(CoT)步骤
- 高强度:包含更详细推理过程的长思维链步骤
总计对不同模块化RAG配置进行了58次评估实验。
研究结果
**实验结果喜忧参半。**在某些配置下,我们观察到适度改善,尤其是在代码生成和(有限程度上的)事实准确性方面。然而,关键指标如信息检索质量和知识提取能力与传统手动调优流程相比基本持平。
**贯穿测试的一个普遍现象是思维链(CoT)推理带来的延迟增加。**虽然深度推理让模型能够分解复杂查询并自我纠正,但代价是迭代工具调用所需的额外时间开销。
**我们发现的最显著挑战是"推理≠经验"这一认知误区:**推理模型尽管能够逐步思考,却缺乏使用检索工具的实际经验。即使采用严格的提示引导,它仍难以检索高质量结果并区分输出好坏。模型经常对使用我们提供的工具犹豫不决,这与去年我们对o1模型的实验结果类似。
这凸显了一个更广泛的问题:推理模型虽然擅长抽象问题解决,但在没有专门训练的情况下优化工具使用仍是一项悬而未决的挑战。
关键发现
我们的实验清晰揭示了"推理≠经验"这一认知误区:**推理模型并不天生"理解"检索工具。**它理解工具的功能和用途,但不知道如何有效使用它,缺乏人类通过实践积累的隐性知识。与传统流程将经验编码到启发式规则和优化中不同,推理模型需要被明确教导如何有效使用工具。
尽管o3-mini能够处理更大的上下文窗口,但在知识提取能力上与4o或Sonnet等模型相比并无显著优势。单纯增加上下文窗口大小并非检索性能提升的灵丹妙药。
**增加模型的推理强度仅略微提高了事实准确性。**我们的数据集主要包含与实际应用场景相关的技术内容,而非数学竞赛题或高级编程挑战。推理强度的影响可能因领域而异,对包含更多结构化或计算复杂查询的数据集可能会有不同表现。
**模型确实出色的一个领域是代码生成。**这表明推理模型在需要结构化、逻辑性输出而非纯检索的领域可能特别有价值。
"推理≠经验"认知误区
我们实验的核心发现是推理模型本身不具备工具使用的专业知识。与精细调校的RAG流程将检索逻辑编码到预定义步骤不同,推理模型每次检索调用都从零开始。这导致效率低下、犹豫不决和次优的工具使用。
为缓解这一问题,我们考虑了几种可能的策略。
进一步优化提示词设计,即以提供更明确指导的方式构建工具使用说明,可能会有所帮助。对工具使用进行预训练或微调也可能让模型熟悉特定检索机制。
此外,混合方法值得考虑,即让预定义的启发式规则处理某些任务,而推理模型则在必要时有选择地介入。
这些想法尚属探索性质,但它们指明了可能弥合推理能力与实际工具使用之间差距的方向。
结论
虽然在我们的应用场景中,基于推理的模块化RAG相比传统流程尚未展现明显优势,但实验确实提供了关于其潜力和局限的宝贵见解。
模块化方法的灵活性仍然极具吸引力。它能提供更强的适应性、更简便的升级路径和对新模型或数据源的动态调整能力。
展望未来,几项值得深入探索的技术包括:
- 采用不同的提示策略和预训练/微调方法,改善模型对检索工具的理解和交互能力
- 在流程的特定环节战略性地使用推理模型,例如用于特定场景或任务,如复杂问题回答或代码生成,而非负责整个工作流的编排
目前,o3-mini等推理模型在合理时间范围内的核心检索任务上尚未超越传统RAG流程。
随着模型技术进步和工具使用策略演进,基于推理的模块化RAG系统可能成为可行的替代方案,特别是对需要动态、逻辑密集型工作流的领域。
阅读原文:点击这里